Microservices – Kommunikation

In den letzten zwei Artikeln der Serie wurden zum einen die organisatorische Sicht sowie die Vor- und Nachteile des Einsatzes der Microservices-Architektur vorgestellt. Nachdem das Team die Entscheidung getroffen hat, den Microservices-Ansatz zu verwenden, müssen grundlegende technische Themen besprochen werden. Schon am Anfang ergibt sich die Frage, wie Microservices miteinander kommunizieren werden. Es gibt verschiedene Wege, die vom konkreten Anwendungsfall abhängen. Das Ziel dieses Artikels ist es, einen Überblick über die Kommunikationsmethoden zwischen Microservices zu verschaffen. Man unterscheidet grundsätzlich zwischen zwei Kommunikationsarten: synchron und asynchron.
Synchrone Kommunikation
Diese Art der Kommunikation wird dann verwendet, wenn der Aufrufer die Antwort sofort braucht und gleichzeitig auf sie wartet. Dieser Ansatz kann technisch mit REST implementiert werden.
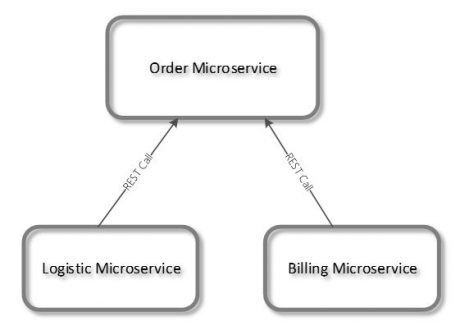
Abbildung 1: Synchrone Kommunikation
In dem obigen Beispiel kommunizieren Logistic- und Billing- mit dem Order-Microservice, um beispielweise die Informationen einer Bestellung zu bekommen. Die Aufrufe sollen nur in einer Richtung verlaufen. Der Order-Microservice darf auf keinen Fall auf die Funktionalität des Logistic-Microservice zugreifen. Dadurch würden zyklische Abhängigkeiten entstehen, die für die Microservice-Architektur negative Folgen hätten. Der größte Nachteil dabei ist, dass eine zu enge Kopplung zwischen Microservices entsteht. Die Verwendung dieser Kommunikationsart sollte zudem immer gerechtfertigt sein. In vielen Quellen wird gerade diese Art der Kommunikation als Anti-Pattern bezeichnet, weil sie zu beträchtlichen Latenzzeiten führen kann.
Ein Microservice kann auch über eine HTTP-Schnittstelle für externe Aufrufe angeboten werden. Die gegenwärtigen Bibliotheken ermöglichen quasi asynchrone Aufrufe von einer synchronen Schnittstelle. Praktisch bedeutet das, dass die die Kommunikation trotzdem synchron bleibt, aber der Haupt-Thread wird nicht blockiert. Das heißt, dass in der Bearbeitungszeit auch andere Operationen ausgeführt werden können. Demgegenüber sollte die interne Kommunikation zwischen Microservices möglichst asynchron verlaufen.
Asynchrone Kommunikation
Man sollte also die asynchrone Kommunikationsart zwischen Microservices bevorzugen. Technisch kann das Konzept mittels Events realisiert werden. Die Abbildung 2 stellt den Prozess dar.
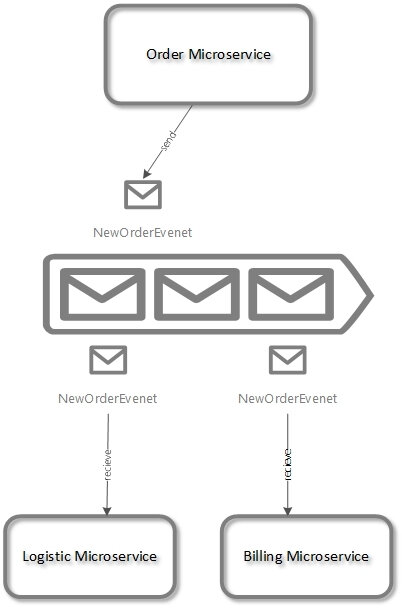
Abbildung 2: Asynchrone Kommunikation durch Verwendung eines Messaging-Systems
Im Mittelpunkt des Diagramms steht ein sogenanntes Messaging-System. An das Messaging-System werden die Nachrichten geschickt, die später von anderen Microservices verarbeitet werden. Der größte Vorteil besteht darin, dass die Microservices komplett voneinander entkoppelt sind. Der Absender kennt den Empfänger der Nachricht nicht. Messaging ist eine gute Grundlage für die Implementierung moderner Architekturen, wie zum Beispiel reaktive Systeme oder Event Sourcing.
Kommunikation durch Datenreplikation
Der Ausgangspunkt dieses Konzepts ist, dass jeder Microservice seine eigene Datenbank besitzt. Die Microservices abonnieren bestimmte Events, die die benötigten Daten beinhalten. Im Rahmen der Verarbeitung von Events werden die Daten in der lokalen Datenbank persistiert. Es ergibt sich zunächst die Frage, ob diese doppelte Datenhaltung effizient ist. In dem Microservice-Ansatz werden die Daten nicht automatisch 1:1 dupliziert. Jeder Microservice besitzt seinen eigenen Bounded Context. Das heißt, wenn ein Event ankommt, werden nur die Informationen verarbeitet und gespeichert, die für den Kontext relevant sind. Die Abbildung 3 stellt diese Art der Replikation dar.
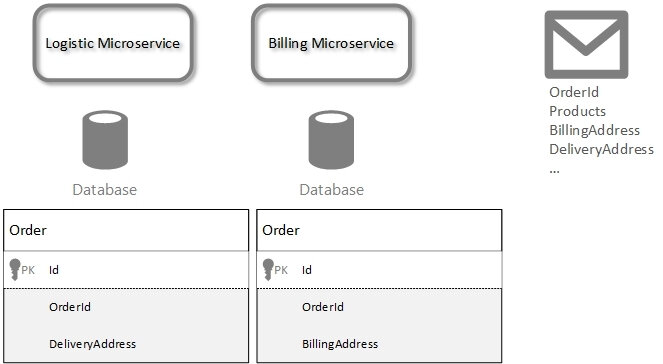
Abbildung 3: Datenreplikation und Bounded Context
Das Event einer neuen Bestellung enthält zwei Adressen: Rechnungsadresse und Lieferadresse. Der Logistic-Microservice speichert die Lieferadresse. Der Billing-Microservice speichert hingegen nur die Rechnungsadresse. In jedem Microservice wird ein unterschiedlicher Bounded Context implementiert und es werden nur die Daten gespeichert, die für die Domäne relevant sind. Dieser Ansatz führt zur besseren Performanz. Wenn die Daten benötigt werden, können sie sofort aus der eigenen Datenbank ausgelesen werden. Dieser Prozess erfolgt ohne jegliche Kommunikation mit anderen Subsystemen. Zum Schluss muss noch eine wichtige Regel erwähnt werden: Es darf nur eine Stelle geben, an der Daten geändert werden können. Wenn diese Regel nicht beachtet wird, dann kommt es zu Inkonsistenzen zwischen beiden Datenbanken. In der Praxis heißt das: Die replizierten Daten dürfen nur von dem Microservice geändert werden, von dem sich ursprünglich stammen. Der Empfänger nutzt die Daten nur zum Lesen.
Fazit
Kommunikation zwischen Microservices ist ein Thema, das gleich zu Beginn des Projektes geklärt werden sollte. Es ist durchaus möglich, mehrere Kommunikationsmethoden zu verwenden, die jeweils zu einem konkreten Anwendungsfall passen. Für eine moderne Architektur mit Microservices scheint aber ein Messaging-System eine wichtige Rolle zu spielen.
Quellen:
[1] E. Wolff: Microservices, Grundlagen flexibler Softwarearchitekturen, dpunkt Verlag
[2] innoQ: Why RESTful communication between microservices can be perfectly fine.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen