Reaktive Anwendungen mit dem Aktorenmodell – Eine Einführung
Die Komplexität reaktiver Enterprise-Anwendungen mit dem Aktorenmodell beherrschbar machen! Darum geht es in dieser mehrteiligen Serie, in der ich das Modell zunächst allgemein und später im Kontext verfügbarer Microsoft-Technologien (Service Fabric) vorstelle.
Alter Wein in neuen Schläuchen?
Das Aktorenmodell wurde schon 1973 von Carl Hewitt, Peter Bishop und Richard Steiger als mathematisches Modell für nebenläufige Berechnungen vorgestellt. Dies geschah zunächst unabhängig von einer konkreten Technologie. Hintergrund war die Idee, Berechnungen von unabhängigen, vernetzten Mikroprozessoren mit eigenem Speicher nebenläufig ausführen zu lassen. Mit dem neuen Modell sollten die vorhandenen Ressourcen effektiver ausgenutzt und folgende Probleme traditioneller Entwicklungsansätze adressiert werden:
- Threads: Für die parallele Ausführung von Berechnungsprozessen werden gemeinhin Threads verwendet. Bei einfachen, nicht-komplexen Aufgaben funktioniert dies gut. Werden die Aufgaben komplexer, so sind auch die entstehenden Systeme schwerer verständlich. Threads werden im System nicht-deterministisch ausgeführt und müssen synchronisiert werden. Hierdurch steigen insgesamt Komplexität und Wartungsaufwand.
- Verteilung: Soll ein System auf mehrere physikalische und/oder virtuelle Maschinen verteilt werden, z. B. um Hochverfügbarkeit zu gewährleisten, so steigt der Aufwand weiter, da zusätzlich Themen wie Load Balancing, Failover und Datenreplikation zwischen Maschinen adressiert werden müssen.
- Shared State: Bezieht sich hier einerseits auf Multi-Threading-Systeme, bei denen alle Threads dieselben Ressourcen im Anwendungsspeicher nutzen, und andererseits auf verteilte Systeme, deren Komponenten alle auf ein gemeinsames Repository, z. B. eine Datenbank, zugreifen. Steigt die Zahl der Anfragen von außen, können leicht Konflikte (Deadlocks) entstehen, was wiederum den Durchsatz des Systems insgesamt reduziert.
Mit der Verbreitung von Mehrkernarchitekturen und zuletzt der zunehmenden Verteilung von Computerressourcen, z. B. in der Cloud, stoßen traditionelle Enterprise-Anwendungsarchitekturen an ihre Grenzen. Dazu kommen immer öfter erhöhte Anforderungen an Reaktionszeit, Fehlertoleranz, Lastverteilung, Durchsatz und Verfügbarkeit. Große Anwendungen wie Facebook, Twitter und viele andere können ein Lied davon singen.
In diesem Kontext stellt das relativ alte Aktorenmodell die konsequente Weiterentwicklung objektorientierter Paradigmen dar. Mit seinen Regeln legt es zudem einen zusätzlichen Fokus auf die Verteilung der Anwendungskomponenten. Vereinfacht gesprochen gibt es dort nur Nachrichten und Aktoren.
Das Aktorenmodell: Alles ist ein Aktor!
Das Aktorenmodell stellt eine Reihe von Regeln auf, die im Folgenden näher betrachtet werden:
- Analog zur objektorientierten Philosophie gilt: Alles ist ein Aktor!
- Aktoren senden eine begrenzte Anzahl von Nachrichten an andere Aktoren, und zwar asynchron.
- Aktoren können Instanzen anderer Aktoren erzeugen, sofern sie deren Adresse kennen.
- Sie können ihr Verhalten während der Laufzeit ändern. (Anmerkung: Dies ist durchaus nicht trivial, wie wir später noch sehen werden).
- Jeder Aktor verwaltet nur seinen eigenen Zustand. Dieser wird nicht mit anderen Aktoren geteilt.
Was bedeutet das?
Die erste Regel macht zunächst den gedanklichen Übergang einfach: Wir können Aktoren als logische Einheiten mit begrenzter Verantwortlichkeit ansehen, ganz wie wir es aus der Objektorientierung gewohnt sind. Im Kontext von Domain-Driven Design zum Beispiel ist jedes Aggregat ein perfekter Kandidat für einen Aktor.
Die zweite Regel besagt, dass eine Kommunikation dieser Einheiten untereinander asynchron über Nachrichten zu geschehen hat. Wir können uns dies wie bei der Post vorstellen, allerdings deutlich schneller. Jeder Aktor hat ein Postfach. Dort werden die von anderen Aktoren gesendeten Nachrichten vom System zugestellt. Jeder Aktor verwaltet sein eigenes Postfach, arbeitet die darin liegenden Nachrichten der Reihe nach ab. Er kann seinerseits Nachrichten an andere, ihm bekannte Aktoren, senden. Hierfür muss er natürlich ebenfalls deren Postfachadresse kennen.
Innerhalb eines Aktorensystems herrscht Location Transparency, d. h. Aktoren wissen nicht, wo genau sie selbst oder andere Aktoren ausgeführt werden. Dies könnte im selben Prozess, auf derselben Machine oder sonstwo sein. Um die Zustellung der Nachrichten über sogenannte Channels kümmert sich das Aktorensystem (analog zur Post). Siehe hierzu auch Abbildung 1.
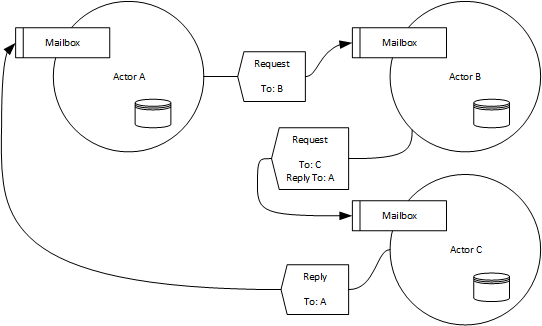
Abbildung 1: Beispiel eines Aktorensystems mit drei Aktoren A, B und C.
Vor- und Nachteile
Die Vorteile des Aktorenmodells liegen auf der Hand:
- Aktoren lassen sich fast beliebig im System verteilen. Ein Aktorensystem ist deshalb beliebig skalierbar. Da der Ausführungsort der Aktoren transparent ist, funktioniert das System weiter, auch wenn sich deren physikalische Adresse innerhalb des (verteilten) Systems während der Laufzeit ändert. Die logische Adresse (das “Postfach”) bleibt stets gleich und das System allein weiß, wo die Instanz des Aktors läuft. Dies wird realisiert, indem Aufrufer nicht mit der Aktorinstanz selbst, sondern mit einer Proxy-Instanz kommunizieren, welche die gleiche Schnittstelle besitzt.
- Da der Zugriff auf einen Aktor über dessen logische Adresse geschieht, kann dessen Implementierung einfach ausgetauscht werden.
- Die explizite Kommunikation über Nachrichten erlaubt es, beliebige Aktorennetze (Topologien) aufzubauen. Darin können weitere logische Komponenten, z. B. Router, Splitter, Aggregatoren oder Prozess-Manager zum Einsatz kommen. Diese sind ihrerseits Aktoren, die Nachrichten nach bestimmten Regeln verteilen, transformieren oder deren Zustellung koordinieren.
- Aktoren teilen untereinander nichts, außer natürlich über den Inhalt der Nachrichten, die sie miteinander austauschen. Diese sind grundsätzlich immutable. Locks auf Ressourcen sind deshalb nicht erforderlich.
- Aktoren können als Zustandsmaschinen eingesetzt werden, da sie ihr Verhalten dynamisch zwischen zwei Nachrichten ändern können.
- Viele Aspekte, die sich mit der Zustellung von Nachrichten, der Verteilung von Aktoren sowie deren Lebenszyklus innerhalb des Systems beschäftigen, werden implizit durch das Aktorensystem verwaltet. Entwickler müssen sich daher normalerweise um diese Aspekte nicht kümmern, sondern können sich stattdessen auf die Lösung des fachlichen Problems konzentrieren. Dies reduziert die Gesamtkomplexität des Systems.
Als Nachteile wären zu nennen:
- Entwickler, die bisher nicht mit dem Aktorenmodell gearbeitet haben, müssen sich zunächst mit dessen Eigenheiten anfreunden.
- Das dynamische Ändern des Verhaltens eines Aktors zur Laufzeit kann die Fehlersuche erschweren, insbesondere bei komplexer Aktor-Zustandslogik.
- Viele Prozesse innerhalb eines Aktorensystems laufen “unter der Haube” ab (z. B. Zustellung von Nachrichten). Dies kann deren Nachvollziehbarkeit erschweren, insbesondere bei der Analyse von Fehlern.
Gibt’s da nicht was von…
Die Popularität des Aktorenmodells ist nicht zuletzt deswegen gestiegen, da es inzwischen in fast allen Umgebungen und Programmiersprachen Frameworks gibt, die das Modell unterstützen. Für Java und Scala ist das Akka Toolkit ein prominentes Beispiel. Es ist dort bereits seit einiger Zeit im Einsatz. In der .NET-Welt sind vor allem die folgenden Frameworks bekannt:
- Akka.NET (Portierung des Akka Toolkits in die .NET-Welt). Das Framework orientiert sich sehr stark an den ursprünglich von Hewitt et al. aufgestellten Regeln. Dies bedeutet insbesondere, dass Aktoren in der Regel keine streng typisierte Schnittstelle für den Nachrichtenaustausch besitzen. Nachrichten sind hierbei explizit definierte (immutable) Datenstrukturen, die über einen Proxy an die Aktorschnittstelle Actor.Tell(object) geschickt werden. In Akka.NET besteht zwar grundsätzlich die Möglichkeit, auch typisierte Aktoren (Typed Actors) zu verwenden, dieser Ansatz ist aber nur in Ausnahmefällen sinnvoll.
- Orleans (Aktoren heißen dort Grains). Das Framework wurde von Microsoft Research ins Leben gerufen, existiert schon etwas länger und weicht in einigen Belangen deutlich von Hewitt et al. ab. Primäres Ziel ist es, sogenannten “Non-Experts” die Umsetzung von verteilten, skalierbaren Anwendungen zu ermöglichen. Einer der Hauptunterschiede zu Akka ist, dass Aktoren (Grains) in Orleans grundsätzlich typisierte Schnittstellen besitzen, d. h. die Funktionalität der Aktoren wird über den Aufruf anwendungsfallspezifischer Methoden mit serialisierbaren Parametern auf dem Proxy getriggert.
- Service Fabric Reliable Actors. Hierbei handelt es sich um die jüngste Implementierung des Aktorenmodells auf der Microsoft-Plattform. Service Fabric Reliable Actors setzen auf Service Fabric Reliable Services auf und können sowohl in der Cloud als auch on-premise gehostet werden. In der Summe unterscheiden sich Orleans und Service Fabric Actors nicht wesentlich voneinander, insbesondere hinsichtlich Typisierung der Aktorschnittstelle (siehe Orleans).
Fazit
Das bereits Anfang der 70-er Jahre entwickelte Aktorenmodell von Hewitt et al. erlebt vor dem Hintergrund fortschreitender Verteilung (Cloud) und komplexerer Anwendungen im Enterprisebereich eine kleine Renaissance. Dies liegt nicht zuletzt an der Tatsache, dass zunehmend mehr Frameworks für dessen Verwendung zur Verfügung stehen. Zu den ältesten Vertretern gehört Akka. Aber auch Microsoft erkennt zunehmend die Bedeutung des Aktorenmodells und stellte mit Service Fabric Reliable Actors jüngst ein weiteres Aktor-Framework auf der Service-Fabric-Plattform vor. In den folgenden Teilen der Serie werden Akka.NET und die Microsoft-Implementierung des Aktorenmodell auf der Plattform Service Fabric näher beleuchtet.
Referenzen
- Carl Hewitt; Peter Bishop; Richard Steiger (1973). “A Universal Modular Actor Formalism for Artificial Intelligence”. IJCAI.
- The Akka Toolkit. http://akka.io/.
- Akka.NET. http://getakka.net/.
- Orleans – A straightforward approach to building distributed, high-scale applications in .NET. http://dotnet.github.io/orleans/.
- Introduction to Service Fabric Reliable Actors. https://azure.microsoft.com/en-us/documentation/articles/service-fabric-reliable-actors-introduction/.
- Orleans and Akka Actors: A Comparison. https://github.com/akka/akka-meta/blob/master/ComparisonWithOrleans.md.
- Comparing Microsoft Orleans and Azure Service Fabric Actors. http://richorama.github.io/2016/07/08/orleans-vs-service-fabric/.