Aus der Praxis: Beschleunigte Analyse von Log-Dateien mit Azure Data Lake Analytics

Vernetzung und Community sind zentrale Elemente der SDX. Ein gutes Beispiel dafür ist die Anfrage eines Kollegen im Kundenprojekt an das gerade neu aufgestellte Data Analytics Team zur Unterstützung bei einem konkreten „Big Data-Problem“.
Dieses „Big-Data-Problem“ und dessen Lösung sollen im Verlauf dieses Artikels beschrieben werden.
Der Hintergrund – Log File Analyse
Im Rahmen des genannten Projekts unterstützen wir unseren Kunden bei der Entwicklung von Software für portable Mitarbeiter-Geräte im produktiven Einsatz. Da die Kunden-Mitarbeiter oft in zeitkritischen Situationen arbeiten, muss die entwickelte Software zum Teil tief in das zugrundeliegende System der Geräte eingreifen, um z.B. die automatischen Windows-Updates durch einen manuellen Patch-Vorgang zu ersetzen. Entsprechend gründlich muss das Verhalten der Anwendung und des Gerätes protokolliert werden, um auftretende Fehler möglichst schnell aufspüren und beheben zu können.
Die dabei entstehende Datenmenge beträgt zwischen 2 und 3 GB pro Device – verteilt über mehr als 1.000 unterschiedliche Einzeldateien wie die Application Logs der einzelnen Anwendungen, diverse Konfigurationsdateien und die von Windows selbst bereitgestellten Eventlogs. Bei etwa 5.000 eingesetzten Geräten entspricht das einer Gesamtdatenmenge von mehreren Terabyte.
Diese Logdateien werden zur einfacheren Übertragung und Speicherung noch auf dem Mitarbeiter-Gerät in zip-Archive komprimiert. Als zentrale Ablage kommt ein NAS-Server im internen Netzwerk des Kunden zum Einsatz. Die Netzwerkanbindung dieses Fileshares verfügt nur über eine begrenzte Bandbreite, sodass der Download der Logdaten auf einen lokalen Rechner zu Analysezwecken erhebliche Zeit in Anspruch nimmt.
Während Auswertungen und Fehleranalysen für einzelne Geräte noch lokal auf dem Rechner des Entwicklers möglich sind und von passenden Tools unterstützt werden, erweisen sich geräteübergreifende Analysen aufgrund der gewaltigen Datenmenge und der technischen Rahmenbedingungen als mühsam und zeitaufwendig. Konkret wurde eine durchschnittliche Vorbereitungszeit von 18 Stunden pro Analyse genannt.
Als weitere Herausforderung stellt sich die Form der Daten. Die meisten der generierten Logfiles bestehen aus Einträgen in der folgenden Form:
<![LOG[Current display settings is Width: [1024], Height: [768], Orientation: [Landscape]]LOG]!><time=“09:03:09.818+000″ date=“01-07-2019″ component=“ SystemManager.Display.DisplayController“ context=““ type=“DEBUG“ thread=“18″ file=“SystemManager.Display.DisplayController.GetCurrentSetting“>
Die Einträge sind eine Kombination aus Freitext-Meldungen mit Parametern sowie Key-Value-Paaren für Meta-Informationen. Für die Analyse müssen oft erst die relevanten Informationen aus den Meldungen extrahiert werden. Als besonderes Hindernis kommt dazu, dass, je nach gewünschter Information, nicht immer alle Daten in einer Zeile stehen, sondern z.T. aus mehreren Zeilen – oder gar aus mehreren Dateien – kombiniert werden müssen (bspw. Beginn und Ende einer Operation). Dies macht den Einsatz eines zustandsbasierten Programms anstelle eines rein zeilenbasierten Skripts zur Auswertung erforderlich.
Die Lösung – Big Data mit Microsoft Azure
Um die Herausforderung der großen Datenmengen und Netzwerkbeschränkungen zu bewältigen, ist die Verschiebung der Analysen in die Cloud eine naheliegende Lösung. Im Rahmen eines Prototypen haben wir verschiedene Ansätze der Speicherung und Extraktion ausprobiert, um die effizienteste und vor allem kostengünstigste Option zu finden.
Die finale Lösung setzt sich aus vier wesentlichen Komponenten zusammen:
- einem Azure Blob Storage für die Ablage der komprimierten Logdaten in der Cloud
- einer Azure Function App zur Extraktion von zu analysierenden Dateien aus den Zip-Archiven
- einem Azure Data Lake Storage, auf dem die extrahierten Dateien zur Analyse abgelegt werden
- und Azure Data Lake Analytics für die eigentliche Auswertung mithilfe von USQL
Die einzelnen Komponenten und die Gründe für die Wahl gerader dieser Services werden in den folgenden Absätzen dargestellt.
Speicherung
Für die Ablage der komprimierten Logdaten in der Cloud fiel die Wahl letztendlich auf einen Azure Blob Storage. Wir haben uns dagegen entschieden, die Archiv-Dateien direkt im Data Lake Storage abzulegen, da letzterer sowohl beim Speicherverbrauch als auch bei Zugriffen merklich teurer ist. Weder der unbegrenzte Speicherplatz noch die größere maximale Bandbreite, mit denen diese Mehrkosten begründet werden, sind für unseren Anwendungsfall relevant. Der Upload der Dateien in die Cloud wird ohnehin durch die Internet-Anbindung des jeweiligen Gerätes begrenzt und das Extrahieren durch die Verarbeitungskapazität der Function App.
Um die Kosten gering zu halten, haben wir uns des Weiteren dagegen entschieden, die Logdaten direkt in extrahierter Form abzulegen. Aufgrund der wesentlich größeren Datenmenge (Faktor 10) gegenüber den komprimierten Dateien und der Vielzahl an Einzeldateien wäre eine solche Vorgehensweise nur dann sinnvoll gewesen, wenn für die Analyse regelmäßig sämtliche oder wenigstens ein Großteil aller Logfiles erforderlich gewesen wären. In der Regel zur Beantwortung einer konkreten Fragestellung aber nur ein bis zwei Dateien pro Archiv benötigt. Deshalb ist es günstiger, nur die jeweils konkret relevanten Dateien bei Bedarf zu extrahieren und zur Weiterverarbeitung auf den Data Lake Storage zu legen.
Extraktion
Für diesen Zweck, das Entpacken einzelner Dateien aus den Zip-Archiven, bietet sich eine Azure Function App an. Ähnlich wie ein Web Job dient eine Azure Function dazu, ein bestimmtes Programm (z.B. in C#, JavaScript, Python o.ä.) direkt in der Cloud auszuführen. Die Ausführung kann dabei zeitgesteuert erfolgen, über einen http-Request angestoßen oder von anderen Ereignis-Quellen (EventHub, ServiceBus etc.) ausgelöst werden. Auch die automatische Reaktion auf das Hochladen einer Datei in einen Blobstorage kann als Trigger verwendet werden. Diesen benutzen wir in einer zweiten Function, um beim Upload ältere Log-Archive desselben Gerätes zu suchen und zu entfernen. Die Azure Function zum Extrahieren der Logdaten reagiert dagegen auf http-Requests, die über ein PowerShell-Skript oder eine beliebige andere Client-Anwendung ausgelöst werden können.
Zur Abrechnung von Azure Functions kann zwischen einem Consumption-Plan und App-Service-Plan gewählt werden. Beim Consumption-Plan wird nach Ausführungen und Rechenleistung bezahlt, beim App-Service-Plan nach gewählter Leistung mit konstantem Preis. Gerade für sporadisch genutzte Functions wie in diesem Fall bietet sich der Consumption-Plan an, da er die größte Flexibilität bietet. (Mehr dazu hat unser Chief eXpert Alexander Jung bereits in einem verwandten Beitrag geschrieben).
Bei der Verwendung des Consumption-Plans sind allerdings die richtige Verteilung der Last sowie die daraus resultierende Laufzeit der Function App von großer Bedeutung. So ist es zwar technisch valide, eine Function zu bauen, die über sämtliche Archive iteriert und aus jedem die gewünschten Dateien extrahiert. Dies ist jedoch nicht zielführend, da Functions im Consumption-Plan nicht auf Mehrkern-Systemen ausgeführt werden und außerdem über ein Laufzeitlimit verfügen. Dies ließe sich zwar über einen anderen Abrechnungsplan ändern, wäre aber wiederum mit tendenziell höheren Kosten verbunden.
Effizienter ist es, für jede Archivdatei einen eigenen Aufruf zu starten. Dadurch wird die Aufgabe der Parallelisierung an das Management der Cloud übergeben. Konkret können von einer Function App im Consumption-Plan gleichzeitig bis zu 200 Instanzen gestartet werden, von denen jede bis zu 100 Requests bearbeiten kann. Das Hochfahren dieser Instanzen und das Verteilen der Requests erfolgt dabei automatisch und ohne Aufwand für den Anwender. (Die angegebenen Zahlen stellen die Standardwerte dar. Sie sind aber für den beschriebenen Anwendungsfall vollkommen ausreichend.)
Mithilfe der Azure Function können die gewünschten Dateien aus den komprimierten Archiven in etwa 30 Minuten extrahiert werden. Das mehrstündige Herunterladen entfällt.
Analyse
Für die eigentliche Auswertung haben wir den Azure Data Lake (ADL) gewählt. Dazu gehören die Komponenten Data Lake Storage (ADLS) als Speicher sowie Data Lake Analytics (ADLA) für die Ausführung von Abfragen gegen die Daten. Beim Anlegen von ADLA muss zwingend ein Data Lake Storage verknüpft werden. Da dieser für die Datenverarbeitung mit ADLA optimiert wurde, ist es sinnvoll, die zu analysierenden Daten auf diesem Speicher abzulegen, auch wenn Data Lake Analytics grundsätzlich auch Dateien vom Blob Storage als Input verwenden kann.
Azure Data Lake Analytics ist gegenüber einem Hadoop- bzw. HDInsight-basierten Ansatz nicht nur einfacher und schneller einzurichten, sondern kann auch wesentlich flexibler skaliert werden. So kann die benötigte parallele Rechenleistung einfach individuell pro Anfrage festgelegt werden. Zugleich entstehen keinerlei Kosten, solange keine Analysen ausgeführt werden – ohne den Service explizit herunterfahren oder löschen zu müssen, wie es bei einem HDInsight- oder VM-Cluster der Fall wäre.
Die Skript-Sprache, die Data Lake Analytics verwendet, wird U-SQL genannt. Sie besteht aus SQL-ähnlichen Queries, in denen Datentypen, Methoden und ganze Klassen aus .Net verwendet werden können. Das reicht von einfachen Methoden nativer Datentypen wie string.Replace() bis hin zur Einbindung eigener Assemblies.
Ein USQL-Skript besteht dabei typischerweise aus drei Arten von Statements:
Extract: Mit EXTRACT werden Daten aus einer Menge gleichartiger Dateien vom Data Lake Storage eingelesen. Dabei können vorhandene Extraktoren (z.B. für CSV-Dateien) oder eigene in C# entwickelte Klassen verwendet werden. Durch die eigenen Klassen können auch nicht-relational strukturierte Daten effizient geladen werden.
Select: SELECT-Statements dienen wie in SQL dazu, Daten zu transformieren, zu filtern oder zu aggregieren. Es gibt auch hier Klauseln wie WHERE, FROM und GROUP BY. Neben dem aus SQL bekannten SELECT gibt es noch weitere verwandte Statements zur Verarbeitung, Projektion und Reduktion von Datensätzen mithilfe von eigenen C#-Klassen.
Output: Analog zu Extract dienen Output-Statements dazu, die verarbeiteten Daten zurück auf den Data Lake Storage zu schreiben. Auch hier können entweder vorhandene Outputter (z.B. für CSV-Dateien) oder eigene Klassen verwendet werden.
Für das Einlesen der Logdaten im oben beschriebenen Format wurde eine eigene C#-Extraktor-Klasse geschrieben. Diese extrahiert pro Zeile den Message-Text sowie die relevanten Metadaten und gibt diese in relationaler Form zurück. Zum Umgang mit Informationen, die über mehrere Zeilen verteilt sind, haben wir zusätzlich eigene Reducer-Klassen implementiert. Diese arbeiten ähnlich wie Aggregations-Funktionen in SQL auf einer Menge gruppierter Zeilen, um daraus eine neue Ergebniszeile zu generieren. Allerdings verarbeiten sie ganze Zeilen anstelle von einzelnen Spalten bzw. Werten.
Die folgende Abbildung zeigt am Beispiel eines Reducers die Definition einer eigenen Klasse für USQL. In diesem Fall werden lediglich Name sowie Laufzeit von ausgeführten Skripten aus verschiedenen, aber zusammengehörenden Zeilen des Logs extrahiert.
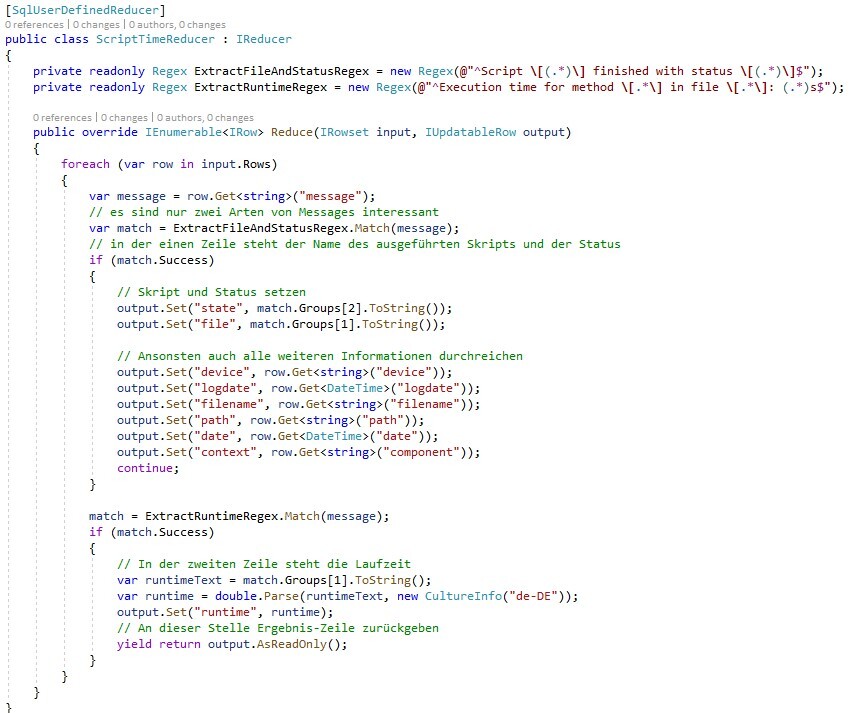
Ein Script, in dem diese Klasse eingesetzt wird, sieht dann wie folgt aus:
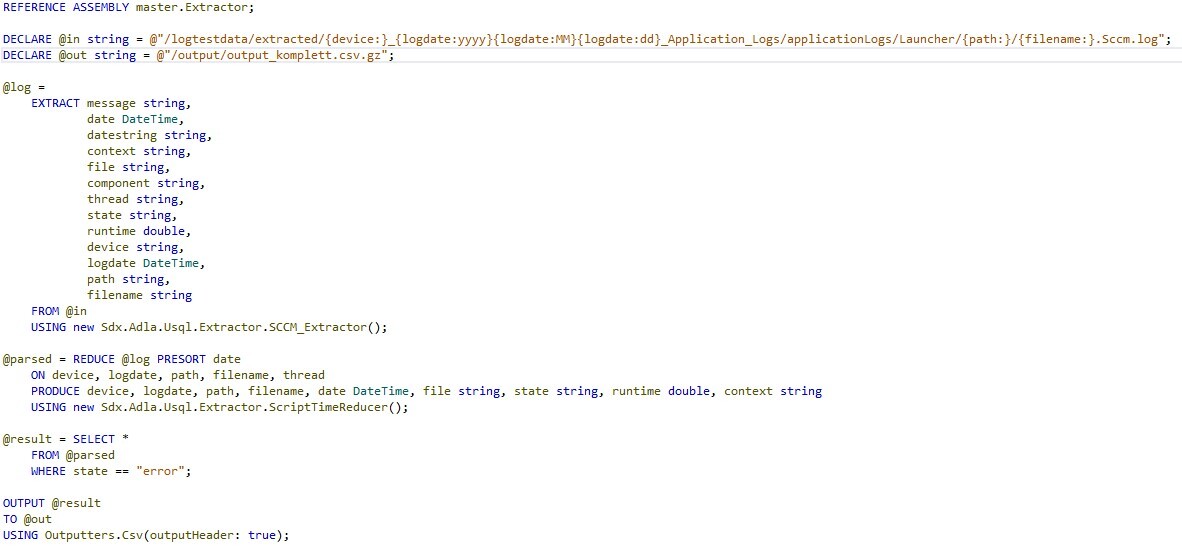
An diesem Skript lassen sich bereits einige interessante Aspekte von U-SQL verdeutlichen:
Als erstes sollte die Ähnlichkeit zu SQL auffallen. Die Sprache wurde mit bewusster Nähe zu SQL entwickelt und ist für Datenbankentwickler entsprechend einfach und intuitiv zu erlernen. Die wesentlichen Unterschiede liegen in der Verwendung von C#-Datentypen und -Ausdrücken sowie dem Lesen und Schreiben aus bzw. in Dateien anstelle von Datenbank-Tabellen.
An der Definition des Input-Pfades lässt sich erkennen, dass ADLA von Haus aus mit flexiblen Dateipfaden umgehen kann. Jeder Ausdruck in geschweiften Klammern ist ein Platzhalter, der entweder beliebige oder definierte Werte (z.B. Jahreszahlen) annehmen kann. Bei der Ausführung werden entsprechend alle Dateien verwendet, die sich über diesen Pfad abbilden lassen. Die jeweils konkreten Werte für die Platzhalter wiederum werden automatisch in die gleichnamigen Spalten des EXTRACT-Statements gefüllt, sodass im Weiteren darauf zugegriffen werden kann.
In diesem Beispiel stimmt der Platzhalter {device:} mit der Kennung des Mitarbeiter-Gerätes überein, von dem die Logfiles ursprünglich generiert wurden, während {filename:} eine konkrete Datei innerhalb des entpackten Archivs beschreibt. Zur Erinnerung: An dieser Stelle liegen die Logdateien bereits unkomprimiert auf dem Data Lake Storage vor. Dateipfade in U-SQL beziehen sich, sofern nicht explizit anders angegeben, auf den zugrundeliegenden Data Lake Storage.
Wenn mehr als eine Input-Datei existiert (sei es über Platzhalter oder mehrere Pfad-Strings), werden diese automatisch parallel verarbeitet. Je nach Typ und Größe können auch einzelne Dateien parallelisiert eingelesen werden (z.B. Dateien mit fester Spaltenbreite).
Sowohl für Input- als auch für Output-Dateien wird nativ das .gz-Komprimierungsformat unterstützt. Dieses muss lediglich in der Dateiendung angegeben werden, damit ADLA die Dateien bei der Ausführung automatisch komprimiert bzw. dekomprimiert. Das ist am Output-Pfad im Beispiel zu sehen.
Des Weiteren zeigt das Beispiel den oben erwähnten allgemeinen Aufbau von U-SQL-Skripten aus Extraktoren, Select-Statements und Outputtern. Sowohl für den Extraktor als auch für den Reducer werden hier eigene C#-Klassen verwendet. An den Namespaces sieht man eine Eigenheit der Sprache: Anders als SQL ist U-SQL komplett case-sensitiv und erlaubt Ausdrücke in Großbuchstaben ausschließlich für Schlüsselwörter. Deshalb darf der Namespace Sdx.Adla.Usql nicht SDX.ADLA.USQL heißen. Außerdem muss jedes Statement zwingend mit einem Semikolon abgeschlossen werden.
Aus dem U-SQL-Skript wird bei der Ausführung ein Job-Graph generiert, ähnlich dem Ausführungsplan von SQL. Die Abbildung zeigt einen solchen Graphen eines abgeschlossenen Jobs.
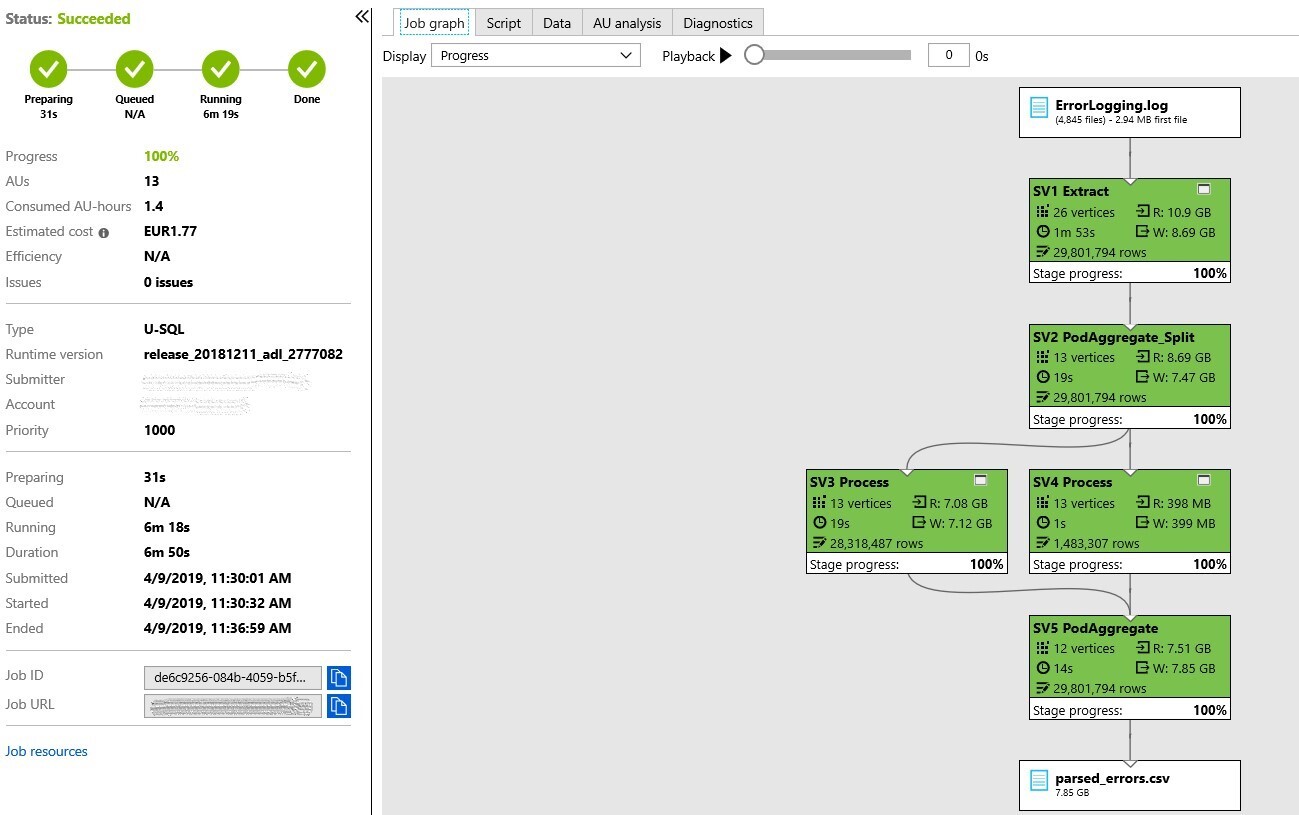
In diesem Fall wurden die Error-Logs von 4.845 verschiedenen Devices eingelesen. Zusammen hatten diese eine Größe von 11 GB. Die Angaben der Vertices sind ein Maß für die Menge an parallelisierbaren Schritten, die der Optimizer vorgesehen hat. In diesem Fall hätte ADLA die 4.845 Dateien also mit bis zu 26 Knoten parallel einlesen können. Die tatsächlich mögliche Parallelität wurde für die Ausführung aber auf 13 AUs (Analytics Units) festgelegt.
Wie in der Abbildung zu sehen, benötigte die Abarbeitung dieser Anfrage über alle Log-Archive hinweg weniger als 7 Minuten. Der Großteil davon wurde für das Einlesen der Daten benötigt. Die meisten Abfragen dieses Projekts bewegen sich in einem ähnlichen Bereich, oftmals sogar schneller. Die Optimierung der Anfrage und insbesondere des eigenen Codes in den C#-Funktionen und -Klassen kann auch hier wesentlich zur Performance beitragen. Für das Testen und Entwickeln können U-SQL-Skripte auch lokal gegen einzelne Dateien ausgeführt werden.
Zusammenfassung
Durch die Verwendung von Microsoft Azure Komponenten war es mit vergleichsweise wenig Aufwand möglich, eine alternative Struktur zur Speicherung, Extraktion und Analyse der Logdaten zu etablieren. Die Verlagerung in die Azure Cloud und die dadurch verfügbaren Ressourcen ermöglichten es, den durchschnittlichen Aufwand für eine geräteübergreifende Loganalyse von mehr als einem halben Tag auf unter eine Stunde zu senken.
Die vorgestellte Lösung ist ein Beispiel dafür, wie in der Azure-Cloud schnell und simpel neue Lösungsansätze ausprobiert, umgesetzt und langfristig etabliert werden können. Insbesondere die Kombination von intuitivem SQL und funktionell mächtigem C# in Azure Data Lake Analytics hat die Auswertung der Logdaten nicht nur schneller, sondern auch wesentlich bequemer gemacht.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen