Getting Started with Machine Learning – Data Engineering

In diesem Artikel möchte ich skizzieren, wie man sich dem Thema Machine Learning (ML) nähern und Wissen aufbauen kann. Dabei werde ich verschiedene Teilschritte anschneiden, die im Prozess der Modellerstellung relevant sind. Insbesondere geht es im ersten Teil um die Vorbereitung der Daten. Als durchgehendes Beispiel dient eine Kaggle Competition, die von Microsoft veröffentlicht wurde.
Kaggle
Kaggle ist eine Online-Plattform für Data Scientists und gehört zu Google. Über die Plattform werden Datasets und ML-Competitions angeboten, an denen angemeldete User teilnehmen können. Einige Competitions sind mit einem Preisgeld versehen, das unter den Teilnehmern mit den besten Ergebnissen ausgeschüttet wird. Bereitgestellt werden die Competitions von den unterschiedlichsten Unternehmen. Die Branchen reichen von Banken bis hin zu wissenschaftlichen Einrichtungen, die zum Beispiel an Hautkrebserkennung forschen.
Neben dem Wettbewerb dient Kaggle auch als Social Media Plattform. User können über die Website ihre Ergebnisse mittels sogenannter Kernels interaktiv präsentieren und so mit Anderen in Kontakt treten und Wissen teilen. Wenn man sich dem Thema Machine Learning bzw. Data Science annähern möchte, ist Kaggle ein guter Weg. Die Kernels liefern Hilfestellung, wie Daten transformiert und angereichert werden können. Daneben bekommt man Informationen, welche ML-Algorithmen am Markt gängig sind und gut performen.
Microsoft Malware Prediction
Microsoft hat in Zusammenarbeit mit Northeastern University und Georgia Tech eine Competition mit dem Titel „Microsoft Malware Prediction“ auf Kaggle veröffentlicht. Die Aufgabe war es, anhand verschiedener Systemparameter, wie zum Beispiel die Version des Windows Defender oder der Windows Edition vorherzusagen, ob ein Gerät zukünftig von Schadsoftware infiltriert wird. Das Trainingsdatenset ist 4 GB groß und enthält 82 Features.
Entwicklungsumgebung
Die folgenden Schritte wurden auf einem lokalen Rechner mit 32 GB RAM durchgeführt. Auf dem Rechner ist eine Anaconda Distribution installiert, welche Pakete der Programmiersprachen Python und R beinhaltet. Im Wesentlichen wird Anaconda zur Verarbeitung von großen Datenmengen, Datenanalyse und wissenschaftlichem Rechnen verwendet. Pakete wie Pandas, Matplotlib oder scikit-learn werden direkt mitgeliefert, es bedarf keiner weiteren Installation.
Als Quelltext-Editor wurde Visual Studio Code mit der Extension „Python“ verwendet. Durch die Extension erhält man IntelliSense und die Möglichkeit, mit Jupyter Notebooks zu arbeiten. Jupyter Notebooks ermöglichen die Definition von „Code Cells“ und die Darstellung von Plots. Jede „Code Cell“ kann einzeln ausgeführt werden. Das Ergebnis wird in einem separaten Fenster dargestellt. In VS Code wird eine Code Cell mit folgenden Zeichen definiert: „#%%“. Als Python Interpreter wurde die zuvor installierte Anaconda Environment ausgewählt.
#%%
# Print Sample Text
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
print("Sample Text")
#%%
# Show Sample Plot
x = [x * 0.01 for x in range(0, 100)]
y = [x**2 for x in x]
plt.title(label='Sample Plot', color='#eae8ed')
plt.plot(x,y, color='#8c56bf')
Explorative Datenanalyse
Im ersten Schritt geht es darum, die Daten zu verstehen und herauszufinden, ob es sich z. B. um nominale oder ordinale Daten, sogenannte kategorische Daten handelt. Diese müssen gegebenenfalls encodiert werden. Daneben gibt es quantitative Daten, die aus Messungen oder Zählungen hervorgehen. Weitere Fragestellungen sind unter anderem Verteilung der Daten, Korrelationen zwischen Feature und Zielvariable, Ausreißer oder Anzahl nicht befüllter Zeilen. In einem Datenset lassen sich in der Regel drei Arten von Qualitätsproblemen beobachten: fehlende Daten, fehlerhafte Datensätze und Ausreißer, sowie widersprüchliche Daten. Sie können das Ergebnis negativ beeinträchtigen.
Die Ausprägung der Zielvariable ist von großer Bedeutung und muss berücksichtigt werden. Sie ist maßgeblich für die Wahl des Algorithmus:
- Ist die Zielvariable im Wertebereich von 1 und 0 (True oder False), sollte die Wahl auf einen Binary Classification Algorithmus fallen.
- Muss man eine Instanz aus mehr als zwei Klassen (z.B. Drama, Komödie oder Thriller) wählen, empfiehlt sich ein Multiclass Classification Algorithmus.
Mit Python und Pandas DataFrames lassen sich Daten gut und einfach analysieren. Es bietet eine Menge Built-In-Funktionalität, mit der man Daten leicht und intuitiv in ein DataFrame einlesen und analysieren kann. Das Einlesen einer CSV-Datei sieht folgendermaßen aus:
import pandas as pd
train_df = pd.read_csv(r"Data\train.csv")
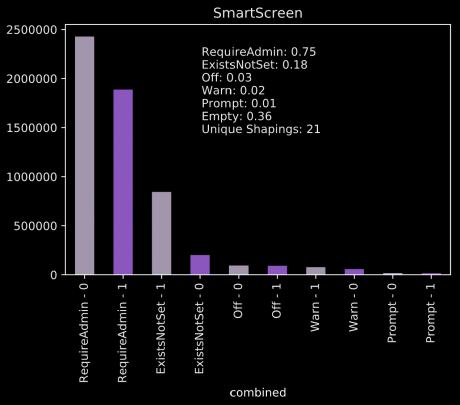
Die Abbildung 2 wurde mit Matplotlib (eine Python-Bibliothek für grafische Darstellungen) erstellt; sie wird für jedes kategorische Feature erzeugt. Gezeigt wird die Häufigkeit der verschiedenen Ausprägungen, gruppiert nach Zielvariable und Ausprägung. Ergänzt wird die Darstellung um ein paar Metadaten, wie z. B. die Anzahl der Null-Werte.
Beim Feature „SmartScreen“ fällt auf, dass innerhalb der Kategorien eine recht hohe Heterogenität herrscht und 36% aller Werte leer sind. Andere Features weisen sogar 99% leere Werte auf.
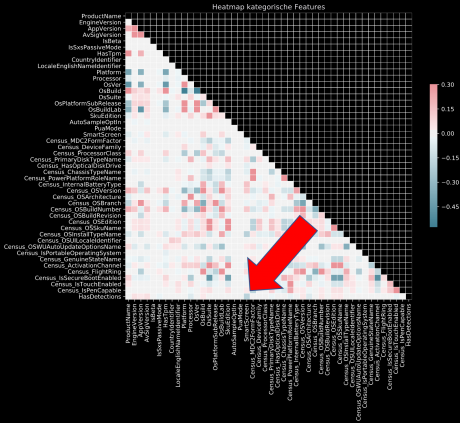
Beim Blick auf das Corrplot wird deutlich, dass das Feature „SmartScreen“ trotz der vielen NULL-Werte die höchste Korrelation mit der Zielvariable aufweist; das Löschen des Features wäre also an dieser Stelle kontraproduktiv.
Data Engineering
Die zuvor beobachten Probleme (z. B. leere Werte oder Ausreißer) müssen behoben werden, um ein gutes Modell gewährleisten zu können.
Daneben müssen Features so angepasst werden, dass sie mit den verwendeten Algorithmen kompatibel sind. Einige können nicht mit String-Werten umgehen; diese müssen zuerst encodiert werden.
Für die Standardaufgaben gibt es Bibliotheken, die einem die Arbeit erleichtern. So bietet die Bibliothek scikit-learn einen Encoder für zeichenbasierte Werte. Im folgenden Codeblock werden alle kategorischen Features encodiert und deren Ausprägung in einen Int-Wert umgewandelt.
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
for feature in categorical_features:
train[feature = le.fit_transform(train_df[feature]).astype(str)
Microsoft hat zu den im Datenset enthalten Features eine Beschreibung beigefügt. Beim Feature „SmartScreen“ findet man eine Beschreibung, wie leere Werte ersetzt werden können. „If the value exists but is blank, the value „ExistsNotSet“ is sent in telemetry.” Für das Feature „SmartScreen“ kann man also leere Werte durch die Ausprägung „ExistsNotSet“ ersetzen. Mit Python und Pandas lässt sich das in einer Zeile schreiben.
train_df['SmartScreen'] = train_df['SmartScreen'].fillna('ExistsNotSet')
Ein weiteres Feature im Dataset ist die „AvSigVersion“ (Anti Virus Signature Version), welche beispielsweise so aussieht: „1.275.552.0“. Microsoft veröffentlicht zu den Versionen die entsprechenden Zeitstempel, womit sich für jeden Datensatz ein Bezug zu der Zeit herstellen lässt. In der Community waren ein paar User so freundlich, die Versionen gegen den jeweiligen Zeitstempel zu mappen und das Ergebnis in einem Python Dictionary bereitzustellen. Im folgenden Codeblock werden Zeitstempel auf die Versionen gemappt und danach in das Date-Format transformiert.
datedictAv = np.load(r'Data\AvSigVersionTimestamps.npy')[()]
train_df['Date'] = train_df['AvSigVersion'].map(datedictAv)
train_df['Date'] = train_df['Date'].map(lambda x: x.date())
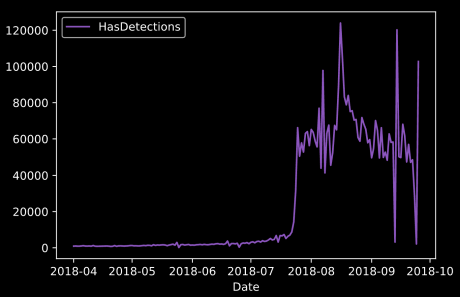
In Abbildung 4 wird ein Plot gezeigt, in dem die Summe aller positiven Labels (1 = hat Virus), gruppiert nach dem Datum, dargestellt wird. Es lässt sich beobachten, dass vor dem 23.07.2018 fast keine Einträge mit Malware-Erkennung vorhanden sind. Möglicherweise ist diese Information auch bedeutsam für das Modell.
Ein Beispiel für ein kontinuierlich quantitatives Feature im Datenset ist die „Census_PrimaryDiskTotalCapacity“ (Größe der primären Festplatte in MB). An ihr lässt sich skizzieren, wie man einen Ausreißer identifizieren und entfernen kann. Der maximale Wert dieses Features beträgt 8.160.436.745.562 MB, was ungefähr 8,16 Exabyte entspricht, ein Wert, der sehr wahrscheinlich nicht plausibel ist. Im folgendem Codeblock wird dargestellt, wie sich solche Ausreißer über den Median und die Standardabweichung suchen und eliminieren lassen.
max_value = train_df['Census_PrimaryDiskTotalCapacity'].median() + \
train_df['Census_PrimaryDiskTotalCapacity'].std() * 0.1
min_value = 10000.0
# Drop rows with ouliers
train_df = \
train_df.loc[(train_df['Census_PrimaryDiskTotalCapacity'] < max_value)\
& train_df['Census_PrimaryDiskTotalCapacity'] > min_value)]
Eine andere Möglichkeit, den Umfang der Daten zu verringern und Störungen zu beseitigen, bietet die Normalisierung. Eine gängige Methode ist die Min-Max-Normalisierung. Bei dieser Methode werden die Daten linear in einen frei wählbaren Bereich, z. B. 0 bis 1, transformiert. In diesem Beispiel wird der maximale Wert auf 1 und der minimale Wert auf 0 geändert. Für diesen Prozess bietet scikit-learn ebenfalls eine entsprechende Klasse an, den „MinMaxScaler“.
Fazit
Die oben beschriebenen Schritte sind notwendig, um vorhandene Daten für ein Machine Learning Modell vorzubereiten. Der meiste Aufwand im Kontext von Machine Learning entfällt dabei auf die Datenanalyse und Data bzw. Feature Engineering. Mit Python, Pandas, Numpy, Matplotlib und scikit-learn erhält man gute Unterstützung und Built-In-Funktionalität, was die Arbeit durchaus komfortabel macht. Darüber hinaus ist der Einsatz von Visual Studio Code empfehlenswert. Durch IntelliSense steigt die Produktivität, mit Jupyter lassen sich Daten interaktiv untersuchen und darstellen.
Im zweiten Teil meines Artikels werde ich zeigen, wie man aus den zuvor bearbeiteten und transformierten Daten ein Modell erstellt. Dabei werde ich neben dem verwendeten Algorithmus (ein Boosted Decision Tree) zeigen, wie sich dessen Parameter mittels GridSearch optimieren lassen.

Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen