Getting Started with Machine Learning – Data Science

Nachdem ich im ersten Teil meines Artikels auf die Plattform Kaggle, Explorative Datenanalyse, Feature Engineering und Data Cleansing eingegangen bin, möchte ich in diesem Artikel beschreiben, wie man einen Machine Learning Algorithmus auswählt, Parameter optimiert und ein Modell erstellt, trainiert und anwendet.
Auswahl des Machine Learning Algorithmus
Die Auswahl hängt sehr stark von der Fragestellung und den vorhandenen Daten ab. Beim ausgewählten Use-Case, der Microsoft Malware Prediction, handelt es sich um eine Binary Classification, mögliche Ausprägungen sind die booleschen Werte „True“ und „False“. Für diese Art der Klassifikation eignen sich einige Algorithmen, unter anderem Support Vector Machine (SVM), Logistische Regressionen, Neuronale Netze oder Entscheidungsbäume. Ein Cheat-Sheet, das bei der Auswahl unterstützt, kann von Microsoft heruntergeladen werden.
In meinem Fall fiel die Wahl auf LightGBM, ein Gradient Boosting Framework, das auf Decision-Tree-Algorithmen basiert. Der Algorithmus wurde im Jahr 2017 von Microsoft veröffentlicht. LightGBM bringt einige Vorteile mit sich, wie GPU-Support, gute Genauigkeit, schnelles Training, Unterstützung zeichenkettenbasierter Features, Umgang mit großen Datenmengen, sklearn-API und Unterstützung von Pandas DataFrames.
Das Ergebnis, ein Entscheidungsbaum, kann man anzeigen und damit nachvollziehen, wie die Daten interpretiert wurden und wie das Modell zu Stande kommt. Das LightGBM-Git-Repository unterliegt der Microsoft Code of Conduct, das bedeutet, Microsoft überwacht die Weiterentwicklung des Frameworks.
Im Gegensatz zu normalen Entscheidungsbäumen ist LightGBM nicht Level-, sondern Leaf-basiert. Leaf-basierte Algorithmen konvergieren schneller, sind allerdings anfälliger für Overfitting. Beim Umgang mit kleinen Datenmengen sollte man nicht unbedingt auf diesen Algorithmus zurückgreifen.
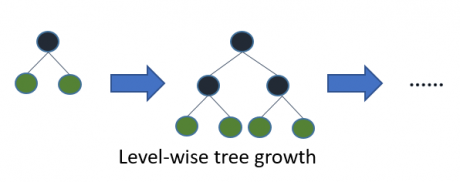
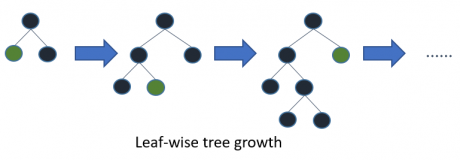
Die Auswahl eines Leafs wird über die maximale Delta Loss getroffen.
Data Preparation
Im ersten Teil des Artikels habe ich bereits die Daten zur Verwendung vorbereitet. LightGBM unterstützt auch String-Werte, sofern die Features vom Datentyp „Category“ sind. Ein Label Encoding ist also nicht weiter notwendig. Die Transformation der kategorischen Werte in den Datentyp „Category“ muss allerdings noch vorgenommen werden, bevor man Modelle erstellen und trainieren kann. Einige Strings sind teilweise groß- und kleingeschrieben, deshalb werden alle Großbuchstaben in kleine Buchstaben umgewandelt. Die Transformationen des Datentyps und die Groß- und Kleinschreibung werden für alle Features durchgeführt, die nicht vom Datentyp „float“ sind.
numeric_features = []
categorical_features = []
numeric_features = [key for key in types if types[key] == 'float64']
categorical_features = [key for key in types if types[key] != 'float64']
for cat in categorical_features:
train_df[cat] = train_df[cat].apply(lambda x: str(x).lower())
test_df[cat] = test_df[cat].apply(lambda x: str(x).lower())
train_df = changeType(train_df,categorical_features,'category')
test_df = changeType(test_df,categorical_features,'category')
Parameter
LightGBM bietet viele verschiedene Parameter, die zur Feinabstimmung des Algorithmus eingesetzt werden können. In der Regel kann man mit den Default-Einstellungen akzeptable Ergebnisse erzielen. Nichtsdestotrotz lohnt es, sich mit den verschiedenen Parametern auseinanderzusetzen.
Je nach Einstellung können Modelle auf Geschwindigkeit oder Genauigkeit optimiert werden. Versucht man die Trainingsgeschwindigkeit zu optimieren, so kann man das „Bagging“ anpassen. Die „bagging_fraction“ bestimmt, welcher Teil der Daten für eine Iteration verwendet werden soll. Per Default werden alle Trainingsdaten verwendet (bagging_fraction == 1.0). Daneben kann auch die „Feature Fraction“ angepasst werden. Setzt man die „feature_fraction“ auf 0.8, so werden nur 80% aller Features verwendet. Die Auswahl der Features wird für jede Iteration neu getroffen und ist zufällig. Daneben sollte man die „max_bin“ (Anzahl Buckets) auf einen kleinen Wert setzen.
Liegt das Augenmerk auf der Steigerung der Genauigkeit, sollte der Parameter „max_bin“ auf einen großen Wert gesetzt werden. Weitere Parameter, die die Genauigkeit positiv beeinflussen, sind „learning_rate“ und „num_iterations“. Zur Verbesserung setzt man die „learning_rate“ auf einen kleinen Wert, „num_iterations“ dagegen auf einen großen Wert. Die Learning Rate bestimmt die Gewichtung der neuen Bäume. Der Parameter „num_iterations“ bestimmt, wie viele Bäume maximal erstellt werden. Um Zeit zu sparen empfiehlt es sich, „Early Stopping“ zu verwenden. Über „early_stopping_round“ lässt sich das Training automatisch stoppen, sofern sich das Modell nicht innerhalb von N Iteration verbessert. Darüber hinaus sollte „num_leaves“ auf einen großen Wert gesetzt werden. Bei dieser Einstellung ist Vorsicht geboten, Anpassungen können zu Overfitting führen.
Weitere wichtige Parameter sind „device“ (CPU oder GPU), „Metrik“ (mae, mse, multi_logloss und binary_logloss), „categorical_feature” (Spaltenindex der kategorischen Features) und „objective“ (u. a. binary für Binary Classification).
Hyperparameter Tuning (Grid Search)
Das Setup der Parameter kann zum Teil mit Grid Search automatisiert werden. Grid Search sucht nach der optimalen Abstimmung der Parameter. LightGBM bietet eine API für die Bibliothek sklearn und die Klasse „GridSearchCV“. Der Programmieraufwand ist an der Stelle folglich gering. „GridSearchCV“ erwartet die zu überprüfenden Parameter mit Ausprägungen und einen initialisierten Classifier. Nach erfolgreicher Ausführung werden die besten gefundenen Parameter bzw. die Kombination, die zum besten Ergebnis geführt hat, ausgegeben.
params = {'boosting_type': 'gbdt',
'max_depth' : -1,
'objective': 'binary',
'num_leaves': 64,
'learning_rate': 0.05,
'n_estimators': 100,
'max_bin': 15,
'reg_alpha': 0.0,
'reg_lambda': 0.0,
'metric' : 'auc'}
param_grid = {
'num_leaves': [150, 650, 1150],
'learning_rate': [0.1, 0.03, 0.2],
'max_bin': [50, 80, 170, 255],
'n_estimators': [100, 900, 1800],
'max_depth': [-1, 15, 65],
'reg_alpha' : [0.7, 1, 1.3],
'reg_lambda' : [0.7, 1, 1.3]
}
estimator = lgb.LGBMClassifier(
silent = True,
verbose_eval=10,
early_stopping_rounds=10,
device_type='cpu',
gpu_device_id=0,
gpu_platform_id=0,
random_state=2019,
objective = params['objective'],
boosting_type= params['boosting_type'],
num_leaves = params['num_leaves'],
learning_rate = params['learning_rate'],
metric = params['metric'],
reg_alpha = params['reg_alpha'],
reg_lambda = params['reg_lambda'],
max_bin = params['max_bin'])
scoring = 'roc_auc'
grid = GridSearchCV(estimator, param_grid,
verbose=1,
scoring=scoring,
refit=True,
cv=2,
n_jobs=-1)
lgb_model = grid.fit(X_train, y_train, eval_set=(X_test, y_test))
print(lgb_model.best_params_, lgb_model.best_score_)
Cross Validation (KFold)
Speziell Entscheidungsbäume sind anfällig für Overfitting. Durch Hyperparameter Tuning steigt die Gefahr von Overfitting. Im Falle von Overfitting weist das Modell hohe Genauigkeit bei den Trainingsdaten auf, nicht aber bei der Gesamtdistribution.
Ursachen sind unter anderem fehlerhafte Trainingsdaten, Ausreißer oder eine zu kleine Trainingsmenge.
Zur Reduzierung von Overfitting kann man Cross Validation einsetzen. Auch für diesen Zweck bietet sklearn ein Modul an, „StratifiedKFold“. Es liefert Indizes zum Splitten eines Datasets in Trainings- und Testdatenset. Ein Split wird auch Fold genannt. Das Verhältnis der Daten ergibt sich aus der Anzahl Folds (1/K). Bei drei Folds (1/3) ergibt sich ein Verhältnis von 67% Trainingsdaten zu 33% Testdaten. Das Splitting wird mehrmals durchgeführt, per Default dreimal (ab v0.22 fünfmal). Nach jedem Split wird ein Modell erstellt und trainiert. Nachdem das Training abgeschlossen ist, kann man bewerten, welcher Fold zum besten Ergebnis geführt hat.
kfold = 5
skf = StratifiedKFold(n_splits=kfold, shuffle=True)
for i, (train_index, test_index) in enumerate(skf.split(train_df, train_label)):
evals_result = {}
print(' lgbm kfold: {} of {} : '.format(i+1, kfold))
print(i)
print(train_index)
print(test_index)
Modell Training
Nach erfolgreicher Durchführung des Hyperparameter Tunings liegen geeignete Parameter für den Algorithmus vor. Aus der Cross Validation geht ein Trainings- und ein Testdatenset mit einem geeigneten Verhältnis hervor.
Die Datasets liegen in Form von Pandas Datasets vor, zur Modellerstellung werden daraus zwei LightGBM Datasets erzeugt. Ein LightGBM Dataset erwartet neben den Features, die Labels, die Featurenamen und eine Liste mit den Namen der kategorischen Features.
dtrain = lgb.Dataset(X_train, label=y_train,
feature_name=feature_names,
categorical_feature=categorical_features)
dtest = lgb.Dataset(X_test, label=y_test,
feature_name=feature_names,
categorical_feature=categorical_features)
Damit sind die Vorbereitungen abgeschlossen und ein Modell kann erstellt und trainiert werden. Die Methode für diesen Zweck heißt „train“. Die Methode erwartet Parameter, Anzahl der Iterationen, ein Trainingsdatenset und zur Validierung ein Testdatenset.
param = {}
param['metric'] = 'auc'
param['max_depth'] = -1
param['max_bin'] = 255
param['num_leaves'] = 150
param['objective'] = 'binary'
param['device_type'] = 'cpu'
param['boosting'] = 'gbdt'
param['learning_rate'] = 0.03
param['reg_alpha'] = 0.7
param['reg_lambda'] = 1.3
num_iterations = 1500
bst = lgb.train(param,
dtrain,
num_iterations,
valid_sets=[dtest],
evals_result=evals_result,
early_stopping_rounds=10,
verbose_eval=100)
Nach abgeschlossenem Training kann das trainierte Modell gespeichert werden. LightGBM bietet zur Persistierung eine Methode („dump_Model“), die das Modell im JSON-Format speichert. Neben der Built-In-Funktionalität gibt es die Möglichkeit, Modelle im Binärformat mit dem Modul „joblib“ zu persistieren und zu laden.
import joblib
joblib.dump(bst, 'predictmalware.pkl')
bst = joblib.load('predictmalware.pkl')
Modell Evalution
Während des Trainings werden die Ergebnisse (AUC) im Intervall von 100 Iterationen ausgegeben („verbose_eval“). Sofern sich das Modell innerhalb von zehn Iterationen nicht verbessert, wird das Training abgebrochen und die beste Iteration ausgewählt („early_stopping_rounds“).
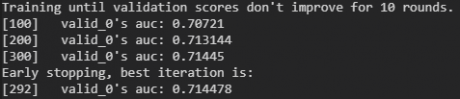
Die Lernkurve kann man sich nach erfolgreichem Training als Plot ausgeben lassen. Im Plot werden die Iterationen und die ausgewählte Metrik (AUC) angezeigt.
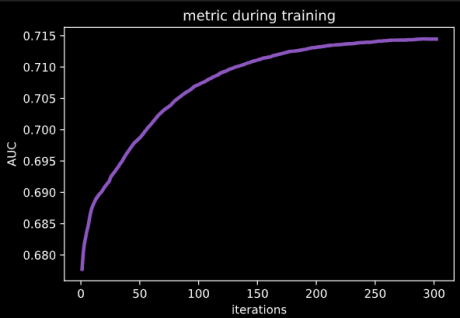
Neben dem Trainingsfortschritt gibt es noch weitere Informationen, die man sich per Plot ausgeben lassen kann, unter anderem den Entscheidungsbaum und die Bedeutung der einzelnen Features. Der Entscheidungsbaum ist bei 81 Features sehr mächtig und schwer lesbar. Im Rahmen einer Auditierung kann es dennoch ein nützliches Instrument sein.
Im Nachfolgenden wird die Bedeutung der einzelnen Features grafisch dargestellt. Das Feature „Date“, das im Zuge des Features Engineerings (siehe Artikel 1) erzeugt wurde, spielt bei der Modellerstellung eine wichtige Rolle.
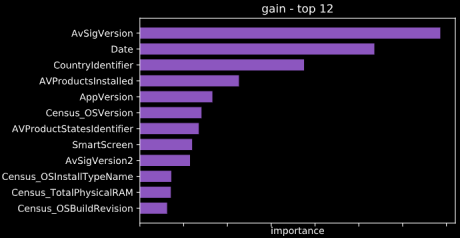
Predict Values
Ein trainiertes Modell wird dazu verwendet, um Daten zu bewerten. Bewertungen werden auf Eingangsdaten mit der Methode „predict“ getroffen. Bei diesem Schritt ist zu beachten, dass die Eingangsdaten strukturell zum Modell passen müssen. Die Struktur wird durch die Trainingsdaten vorgegeben. Für den Parameter „num_iteration“ sollte die Iteration mit dem besten Ergebnis gewählt werden. Als Ergebnis liefert die Methode „predict“ ein Numpy-Array mit float-Werten im Wertebereich von 0,0 bis 1,0. Werte die größer als 0,5 sind, können dem Label „True“ zugeordnet werden, kleinere dem Label „False“.
predictions = bst.predict(test_df, num_iteration=bst.best_iteration)
Fazit
Aufmerksam wurde ich auf den Algorithmus durch Kaggle. Im Vergleich zu anderen Algorithmen performt LightGBM gut. Positiv ist mir auch die Trainingsgeschwindigkeit aufgefallen. Mit GPU-Training wäre es sicher noch schneller gegangen. Die Schnittstellen ermöglichen einfache Einbindung gängiger Module und ersparen zusätzlichen Programmieraufwand.
Mit der Verwendung von „GridSearchCV“ kann man die Suche nach einem guten Parameterset sehr stark automatisieren. Dabei ist zu beachten, dass „GridSearchCV“ alle möglichen Parameter-Kombination durchprobiert, je nach Anzahl Parameter und Ausprägungen kann die Zahl der Ausführungen groß werden und der Prozess sehr langwierig sein.
Auch der eigentliche Trainingsprozess kann je nach Größe der Trainingsdaten und Hyperparametern sehr lange dauern. Allgemein ist es ratsam, rechenintensive Prozesse, wie Training und Hyperparameter-Tuning, in eine virtuelle Maschine auszulagern. Eine andere Möglichkeit ist die Verwendung von Azure Machine Learning Service. Mit diesem Service lässt sich Rechenleistung nach Bedarf beziehen und ein trainiertes Modell als Web Service bereitstellen. Durch Einbindung in einen Web Service wird der Modellzugriff flexibel und einfach.

Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen