Serverless Blazor Applications: Serverloses Hosting auf Azure

Im Rahmen einer dreiteiligen Flurfunkserie zeige ich, wie mithilfe von ASP.NET Blazor und Microsoft Azure schnell und effizient serverlose Web-Anwendungen in .NET entwickelt und bereitgestellt werden können.
In diesem ersten Teil geht es ausschließlich um das serverlose Hosting. Das gezeigte Vorgehen lässt sich ohne Weiteres auch auf andere Single Page Applications (z.B. in Angular, React, …) übertragen. In den nachfolgenden Artikeln werde ich aber auch auf die konkrete Entwicklung mit Blazor eingehen und zudem zeigen, wie ein serverloses Backend inklusive Datenbank und Realtime-Updates auf Azure aussehen kann.
Zum Verständnis zuerst ein Überblick über die Begriffe Serverless und Blazor:
Was bedeutet Serverless?
Serverless bedeutet, eine Anwendung ohne den Einsatz beziehungsweise die Zuweisung fester Ressourcen zu betreiben, das heißt ohne einen dedizierten physischen oder virtuellen Server. Stattdessen werden Ressourcen für die Ausführung bei Bedarf automatisch – also ohne explizite Mitwirkung der Anwendung oder des Entwicklers – zugewiesen und anschließend wieder für andere Zwecke freigegeben. Ein solches Vorgehen findet insbesondere in Cloud-Umgebungen wie Microsoft Azure statt, wo die vorhandene physische Rechenleistung von vielen Kunden gleichzeitig in Anspruch genommen wird und eine bedarfsgesteuerte Umverteilung entsprechend zu einer effizienteren Auslastung führt.
Ein Beispiel für ein klassisches, server-basiertes Hosting wäre die Bereitstellung einer (Web-) Anwendung in einer Virtuellen Maschine oder auf einem Azure Web Service. Hier werden konkrete Ressourcen dauerhaft für den Betrieb der Anwendung reserviert, sodass auch dann Kosten entstehen, wenn gerade kein Zugriff erfolgt.
Mithilfe von serverlosen Architekturen wollen wir dieses Problem lösen und eine effizientere Verwendung von Ressourcen erreichen.
Was ist Blazor?
Dieser Artikel beschäftigt sich explizit nicht mit der Entwicklung von Blazor-Anwendungen, sondern mit dem Hosting auf Azure. Dennoch möchte ich kurz einen Überblick darüber geben, was sich hinter dem Namen genau verbirgt und wo der Unterschied zu bisherigen ASP.NET-Anwendungen liegt.
ASP.NET Blazor ist ein Single Page Application Framework, mit dem sich interaktive Web-Anwendungen in .NET entwickeln lassen. Als Single Page Applications bezeichnen wir Web-Anwendungen, die nur aus einer initialen HTML-Seite bestehen und sämtliche Änderungen mithilfe von lokalem Code durchführen. Es kommt also nie zu einem Neu-Laden der Seite wie bei statischen oder Server Page-Anwendungen. Dafür muss allerdings der gesamte Anwendungs-Code beim initialen Aufruf heruntergeladen werden.
Bisher war JavaScript die einzige Möglichkeit, solche Client-Logik browser-nativ zu implementieren (also ohne zusätzliche Plugins wie Silverlight, Java oder Flash). Mit ASP.NET Blazor wird erstmals auch eine Umsetzung in C# möglich – mit Zugriff auf das gesamte .NET-Ökosystem inklusive NuGet-Bibliotheken. Dies funktioniert auf zwei verschiedenen Wegen:
Blazor Server
Die erste Variante von ASP.NET Blazor ist serverbasiert und wurde mit dem Release von .NET Core 3.0 veröffentlicht. In diesem Fall läuft die eigentliche (.NET)-Anwendung wie eine klassische ASP.NET-Webseite auf dem Webserver (IIS, Azure Web Service, …). Interaktionen und Events auf Client-Seite werden über eine SignalR-Verbindung an den Server übermittelt und dort verarbeitet. Anschließend wird dem Client ebenfalls über SignalR mitgeteilt, welche Elemente der GUI sich entsprechend des Ereignisses verändert haben.
Der Browser führt in dieser Variante also weiterhin nur JavaScript-Code aus, der Entwickler braucht sich darum jedoch nicht zu kümmern, sondern kann seine Anwendung vollständig in C#/.Net implementieren.
Vorteilhaft ist dabei, dass sämtliche Anwendungs-Logik auf dem Server verbleibt und so die physische Trennung zwischen Client und Backend entfällt. Damit ist die Anwendung auch weitgehend unabhängig von der Leistungsfähigkeit oder Aktualität des Client-Browsers. Nachteilig ist die ständige Verbindung zwischen Server und Client, die zum einen Performance kostet und zum anderen keine Offline-Funktionalität in der App unterstützt.
Die permanente, aktive Verbindung zum Backend sowie die Ausführung der Programmlogik auf dem Server schließen außerdem ein serverloses Hosting in diesem Modell aus. Für die Bereitstellung von Blazor Server braucht es einen aktiven und permanent verfügbaren Server wie zum Beispiel einen Azure Web Service.
Blazor Client
Demgegenüber steht die Alternative Blazor Client, die im Mai 2020 für .NET Core 3.1 veröffentlicht wurde und auf WebAssembly basiert. WebAssembly ist ein Web-Standard, der die Ausführung von kompiliertem C++-Code im Browser ermöglicht und nativ von allen modernen Browsern unterstützt wird. Ursprünglich angedacht war der Einsatz von WebAssemblies für komplexe und performance-kritische Berechnungen wie mathematische Funktionen oder Machine-Learning, die von den Vorteilen kompilierten Maschinen-Codes profitieren. Ein Verlassen der Browser-Sandbox wird allerdings auch in WebAssemblies verhindert.
Blazor Client nutzt die Funktionalität von WebAssembly, um die .NET-(Mono-)Runtime im Browser auszuführen und auf dieser dann den .NET-Code der eigentlichen Anwendung. Der dafür zu entwickelnde Code gleicht dem aus der Blazor Server-Variante, es ändert sich lediglich das Hosting-Modell.
Für den Anwender bedeutet diese Architektur, dass beim initialen Aufruf einer Blazor Client-Webseite zuerst sowohl die Mono-DLL als auch sämtliche Anwendungs-Bibliotheken heruntergeladen werden müssen. Dies kann insbesondere bei mobilen Verbindungen von Nachteil sein.
Zugleich ist die Anwendung dadurch nicht spezielle auf Software oder Browser-Plugins auf dem Client-Rechner angewiesen (wie zum Beispiel Silverlight oder Java). Da die App ihre Runtime selbst mitbringt, muss kein .NET installiert sein.
Zudem läuft eine Blazor Client-Anwendung wie eine in JavaScript geschriebene Single Page Application komplett im Browser des Anwenders. Das bedeutet zum einen, dass volle Offline-Fähigkeit unterstützt wird, und zum anderen, dass aufseiten des Web-Servers kaum Rechenleistung erforderlich ist. Es müssen nur die statischen Daten der Anwendung in Form von HTML-, CSS-, und DLL-Dateien ausgeliefert werden.
Den letzten Punkt wollen wir uns im Folgenden zu Nutze machen.
Serverless Blazor
1. Anlegen einer Blazor Client Anwendung
Da ich in diesem Artikel nicht tiefer in die eigentliche Entwicklung mit Blazor einsteigen möchte, begnügen wir uns mit der Beispiel-Anwendung. Sie kann, wie hier beschrieben, in wenigen Schritten über die Kommando-Zeile erzeugt werden. Alternativ gibt es auch Templates für Visual Studio.
- Zuerst ist das SDK für .NET Core 3.1 erforderlich.
- Dann sollten die Blazor Templates installiert werden (Stand Mai 2020, am besten die aktuelle Version von der Webseite verwenden und auf das jeweils erforderliche .NET Core SDK achten):
dotnet new -i Microsoft.AspNetCore.Components.WebAssembly.Templates::3.2.0
- Anschließend kann die Beispielanwendung erzeugt werden:
dotnet new blazorwasm -o BlazorSample
und nach einem Wechsel in den Ordner BlazorSample mit
dotnet run
ausgeführt werden.
Im Browser kann die Anwendung aufgerufen werden (standardmäßig unter http://localhost:5000):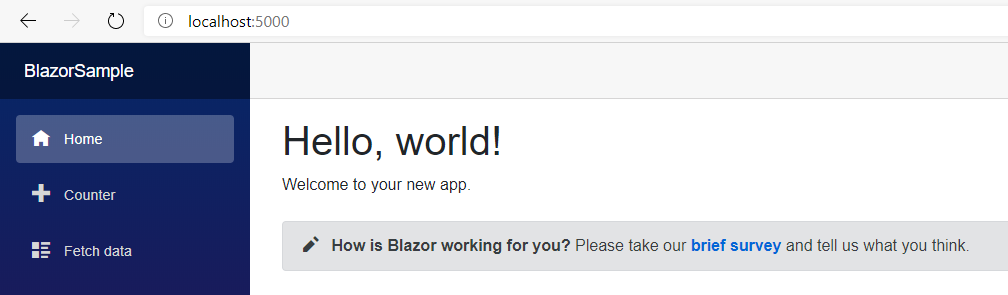
Durch das Klicken auf die Menu-Elemente können wir in der Anwendung navigieren, ohne dass es zum Neuladen kommt. Genauso können wir unter „Counter“ einen Zähler innerhalb der Anwendung hochzählen, ohne dass eine Kommunikation mit dem Server nötig wäre. Dies wirkt trivial, ist aber insofern bemerkenswert, dass eine Umsetzung dieser Logik auf dem Client bisher nur in JavaScript möglich war. Im klassischen ASP.NET hätten wir dagegen bei jedem Klick auf den Counter-Button die komplette Seite neu generieren und außerdem auf dem Server den aktuellen Zählerstand speichern müssen.
In den Developer-Tools des Browsers können wir sehen, welche Dateien beim ersten Aufruf der Seite heruntergeladen werden:

Neben den HTML- und CSS-Dateien sehen wir hier vor allem die .NET-Runtime in Form der dotnet.wasm sowie die DLL unserer Anwendung zusammen mit allen referenzierten DLLs (System.dll, …), ganz wie bei einer gewöhnlichen .NET Core-Anwendung. Nach dem initialen Download können wir in der Anwendung arbeiten, ohne dass es zu einer weiteren Verbindung mit dem Server kommt. (Mit Ausnahme des HTTP-Calls unter „Fetch Data“).
Unsere Anwendung besteht also ausschließlich aus statischen Dateien, die vom Browser des Users heruntergeladen und interpretiert bzw. ausgeführt werden.
2. Bereitstellen der Anwendung
Um die Anwendung zu hosten, brauchen wir lediglich diese statischen Dateien an einem passenden Ort bereitzustellen. Der Azure Storage Account bietet dafür die nötige Funktionalität, inklusive HTTPS.
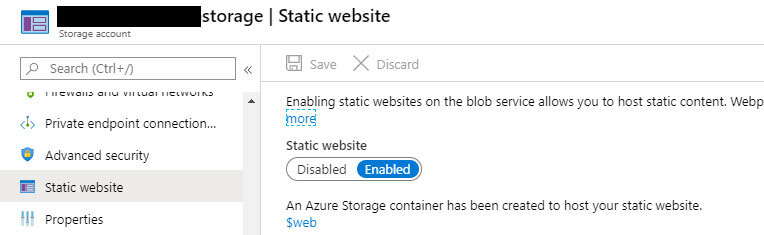
Die Konfiguration als statische Webseite lässt sich wie im obigen Bild über das Azure-Portal vornehmen. Im Rahmen dieses Artikels verwenden wir allerdings einen anderen Weg und lassen Visual Studio Code die Arbeit für uns machen.
Zuerst erzeugen wir einen Build unserer Anwendung mit dem Befehl
dotnet publish -c Release -o ./publish
Dann benötigen wir Visual Studio Code mitsamt der Azure Storage-Extension. Ein neuer Storage-Account kann entweder über das Portal angelegt werden oder im Folgenden direkt beim Publishing:
Die Azure Storage-Extension erlaubt es uns, einen beliebigen Ordner als statische Webseite auf einen Azure Storage zu deployen. In diesem Fall muss es der wwwroot-Ordner (unterhalb von publish) unserer gebauten Anwendung sein, wie im Bild zu sehen:
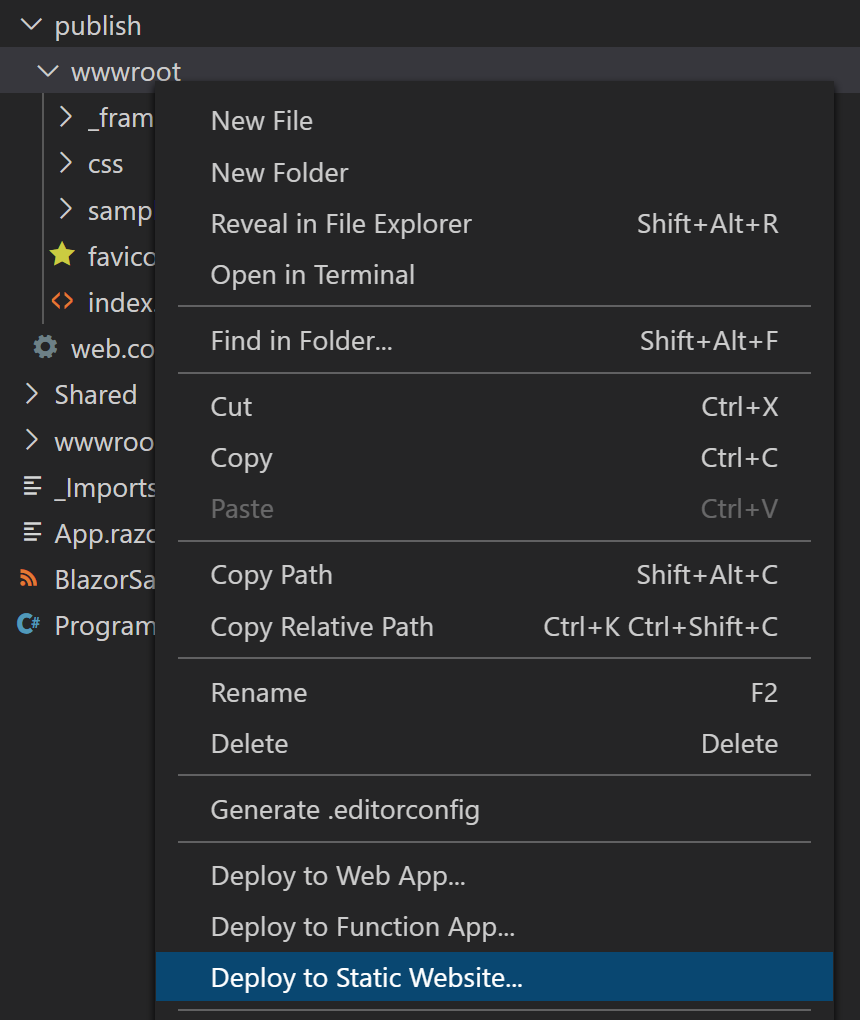
Hier kann entweder ein bestehender Storage Account ausgewählt oder ein neuer erzeugt werden. Im Fall eines bestehenden Accounts erfolgt nun die Frage, ob und wie der Storage für die Verwendung als statische Webseite konfiguriert werden soll. Hier sollte als Index-Dokument die index.html-Datei und als Error-Dokument nichts angegeben werden (darauf kommen wir später noch zurück).
Nach erfolgreichem Deployment können wir zum Web-Endpoint unseres Blob-Storages navigieren und sehen unsere Beispiel-Anwendung, nun für jeden erreichbar, der die Adresse kennt:
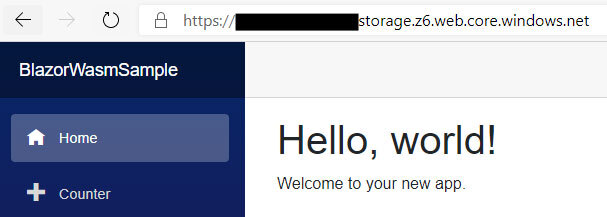
Wie zuvor auf dem lokalen Rechner können wir hier auf die Navigations-Elemente klicken und den Counter-Button betätigen. Die Anwendung läuft in unserem Browser und funktioniert selbst dann weiter, wenn wir die Internet-Verbindung trennen oder den Storage Account löschen.
Es gibt allerdings eine Sache, die nicht funktioniert:
3. Routing
Wenn wir von der Hauptseite der Anwendung auf „Counter“ klicken, verhält sich die Anwendung wie erwartet. Die entsprechende Seite wird angezeigt und es ändert sich die URL in https://[storage_account]/counter
Geben wir diese Adresse allerdings manuell ein, erhalten wir einen Fehler (vorausgesetzt, die Konfiguration ist wie oben beschrieben erfolgt):
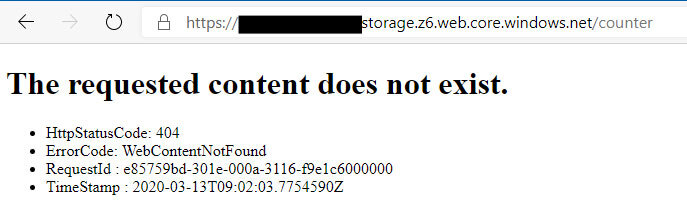
Dies liegt daran, dass der Storage Account sich weiterhin wie ein File-System verhält. In diesem Fall wird also versucht, eine Datei oder ein Verzeichnis mit dem Namen counter unterhalb des root-Verzeichnisses ($web) zu finden. Ein solches Verzeichnis gibt es aber nicht. Das Routing auf unsere eigentliche Counter-Seite findet ausschließlich innerhalb der Logik unserer Anwendung statt. Dazu müsste der Blob Storage aber zuerst die Anwendung selbst ausliefern.
Es gibt zwei unterschiedliche Möglichkeiten, das Problem zu beheben:
Verwenden einer Error-Page
In der Konfiguration unseres Storage Accounts als statische Webseite haben wir das Feld für Error-Page leer gelassen. Die erste und unsaubere Option, das Routing-Problem zu lösen, besteht darin, im Fall eines Fehlers ebenfalls auf die index.html zu verweisen. Dies kann über das Portal auch nachträglich konfiguriert werden.
Tun wir das, verweist die URL immerhin auf die richtige Unter-Seite unserer Anwendung. Allerdings erhalten wir bei einem solchen Aufruf trotzdem einen 404-Fehler in der Konsole.
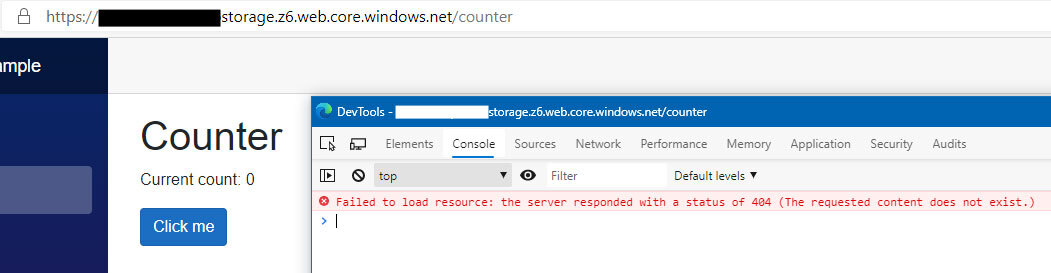
Für wen das kein Hindernis darstellt oder wer ohnehin keine direkte URL-Navigation innerhalb seiner Applikation benötigt, der hat an dieser Stelle eine vollständig funktionsfähige Single Page Application in .NET Blazor auf Azure gehostet.
Für alle, die mehr Wert auf das korrekte Verhalten ihrer Anwendung legen, gibt es eine aufwendigere aber letztendlich vorteilhafte Vorgehensweise:
Azure CDN
Ein CDN (Content Delivery Network) dient dazu, Inhalte von Webseiten zu cachen und in physischer Nähe zum Aufrufer bereitzuhalten. Dies gewährleistet sowohl eine geringere Verzögerung für den Nutzer als auch eine geringere Last auf dem eigentlichen Anwendungsserver. Natürlich ist dies nur für statischen oder deterministischen Content sinnvoll.
Das Azure CDN bietet eine solche Funktionalität. Darüber hinaus lässt sich – je nach ausgewähltem Plan – mithilfe von Regeln Einfluss auf das Ergebnis von Aufrufen nehmen. Für unseren Fall interessant ist die Möglichkeit von URL Rewrites.
Dazu erstellen wir zuerst ein Azure CDN Profile. An dieser Stelle muss darauf geachtet werden, dass als Pricing Tier „Premium Verizon“ ausgewählt wird. Dies ist die einzige Option mit der Möglichkeit für URL Rewrites.
Im gleichen Schritt oder anschließend kann ein Endpoint definiert werden. Dieser muss vom Typ „Custom origin“ sein (nicht „Storage“, auch wenn das naheliegender wäre) und auf die URL unserer Anwendung auf dem Blob Storage verweisen (ohne Protokoll davor).
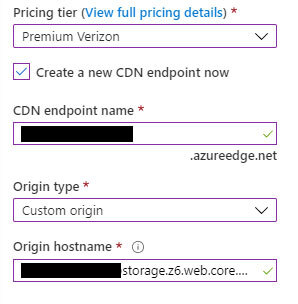
Anschließend kann die Webseite über den neuen Endpunkt ([endpointname].azureedge.net) aufgerufen werden. Es kann ein paar Minuten dauern, bis tatsächlich der erwartete Inhalt geliefert wird. Bisher leitet das CDN unsere Aufrufe allerdings nur 1:1 weiter. Das manuelle Anfügen von /counter am Ende der URL führt also weiterhin zu einem Fehler.
Um den URL-Rewrite zu definieren, müssen wir in das Verizon-Portal. Das ist über den Button „Manage“ im CDN Profil (nicht im Endpunkt) erreichbar. Hier im Menu „HTTP Large“ auf „Rules Engine“ klicken. Dann lässt sich eine neue Regel definieren. Wir müssen ein neues Feature mit dem Klick auf das entsprechende „+“ hinzufügen und „URL Rewrite“ auswählen. Danach können wir bestimmen, welche Arten von URLs wir wohin umleiten wollen. In unserem Fall wollen wir alle Anfragen, die nicht auf Dateien abzielen (z.B. muss „/_framework/wasm/dotnet.wasm“ weiterhin die korrekte Datei liefern), auf die index.html umleiten, damit die Blazor-Anwendung dann das eigentliche Routing übernehmen kann.
Dazu können wir die einfache Regel [^.]*$ in das Source-Feld eintragen und „index.html“ in das Destination-Feld.

Hinweis: Diese Regel leitet alles auf die index.html-Datei um, was keinen Punkt enthält. Für die meisten Blazor-Anwendungen sollte das reichen. Falls jedoch geplant ist, Query-Parameter mit Punkt zu verwenden (z.B. ?date=01.01.2020), dann muss die Regel erweitert werden. In dem Fall funktioniert [^?.]*(\?.*)?$ als Source.
Credit an dieser Stelle an folgenden Artikel, aus dem diese Regel stammt und der mir auf dem Weg sehr geholfen hat: https://medium.com/@antbutcher89/hosting-a-react-js-app-on-azure-blob-storage-azure-cdn-for-ssl-and-routing-8fdf4a48feeb
Die Anwendung der Regel kann bis zu vier Stunden dauern. Danach sollte das Routing über den Endpoint wie gewünscht funktionieren:
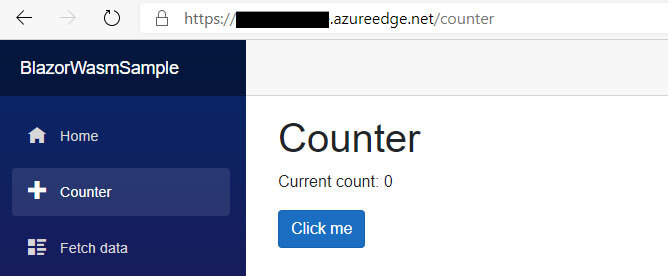
4. Caching fixen
Nun funktioniert also alles. Oder?
Tatsächlich gibt es noch ein Problem. Dieses manifestiert sich allerdings erst dann, wenn wir versuchen, unsere Anwendung zu updaten. Denn wie beschrieben cached das CDN die gelieferten Daten für den Aufrufer, sodass zukünftige Aufrufe nicht mehr auf den eigentlichen Storage zugreifen müssen. Leider cached es sie so gut, dass der Aufrufer auch nichts davon mitbekommt, wenn sich der Inhalt dieser Dateien (also der Code unserer Anwendung) ändert.
Dies scheint insbesondere ein Problem mit Nicht-Web-Dateien zu sein, also konkret den DLL-Files unserer Blazor-Anwendung. Während Änderungen an der index.html nach ein paar Stunden vom CDN erkannt und übernommen werden, wurden geänderte DLL-Files z.T. auch nach mehreren Tagen nicht neu ausgeliefert. Auch der „Purge“-Button im Azure Portal, der eigentlich den Cache des CDNs leeren sollte, zeigte keine Wirkung. Möglicherweise funktioniert er nicht für Verizon-CDNs.
Es gibt jedoch eine Möglichkeit, das Caching-Verhalten des CDNs über den CacheControl-Header der Dateien zu steuern. Dies kann beispielsweise über eine Azure Function mit Blob-Trigger erfolgen:

Wobei „cacheHeader“ ein string der Form „public, max-age=3600“ ist und die Anzahl an Sekunden angibt, die die Datei im Cache verbleiben darf. Zu beachten ist dabei natürlich, dass eine geringere Zahl die Umsetzung von Änderungen beschleunigt, aber auch den Performance-Vorteil des CDNs reduziert.
Wenn die Anwendung über eine CI-Umgebung (z.B. Azure DevOps) deployed wird, bietet es sich an, stattdessen ein PowerShell-Skript zu verwenden, um den Header direkt beim Kopieren der Dateien zu setzen.
Zusammenfassung
Wie gezeigt, bietet Microsoft Azure als Cloudplattform einige interessante Möglichkeiten, um Single Page Applications – wie ASP.NET Blazor-Anwendungen – schnell, einfach und kostengünstig zu hosten. Zwar sind dabei einige Hindernisse zu überwinden – oder Einschränkungen hinzunehmen –, die werden aber durch die sehr geringen Kosten im Vergleich zu einem klassischen Server-Hosting wieder wettgemacht.
Insgesamt liegen die minimalen Kosten für eine komplette Anwendung wie hier beschrieben bei ca. 20ct im Monat – und dürften selbst bei wachsenden Zugriffszahlen vergleichsweise langsam steigen. Weiterhin kommt dazu, dass Azure in diesem Szenario die erforderlichen Ressourcen bei steigender Last automatisch bereitstellt. Anders als bei einer virtuellen Maschine oder einem Service-Plan sind hier keine manuellen Anpassungen an der Leistungsfähigkeit nötig.
Ausblick
Die Anwendung in unserem Beispiel ist relativ simpel. Es ist jedoch nicht schwer, sie um weitere Funktionalität zu erweitern. In zwei folgenden Artikeln werde ich beschreiben, wie sich mithilfe von Azure Functions und dem Azure SignalR-Service eine serverlose Chat-Anwendung in Blazor entwickeln lässt.

Michel Richter
Senior eXpertSie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen