Ein Microsoft-Mitarbeiter hatte einen Kommandozeilenbefehl zum Update einer Router-IP-Adresse abgesetzt. Dies hatte folgende Auswirkungen: Der betroffene Router informierte alle anderen Router im Netzwerk von der Adressänderung, diese wiederum begannen mit einer Neuberechnung der optimalen Routen im Netzwerk, was in der Folge zu hohen Latenzzeiten in der gesamten Netzwerkkommunikation führte.
Cloud-Ausfall bei Azure
Resilient Software Design • Azure Services

Der 25.01.2023 war kein guter Tag für Microsoft. Ab 08:05 Uhr (07:05 UTC) wurden massive Ausfälle aller Services beobachtet – Teams, Exchange Online, Azure Portal, SharePoint Online – nahezu alles war von hoher Netzwerk-Latenz und Timeouts betroffen. Das eigentliche Problem war nach ca. 2 Stunden (gegen 09:00 UTC) behoben, Service-Auswirkungen waren aber in Teilbereichen noch bis ca. 13:45 Uhr (12:43 UTC) zu spüren.
Die Aufmerksamkeit war dramatisch. Heise Online titelt in einem „Kommentar zum Cloud-Ausfall bei MS: Ist der Patient schon tot oder nur lädiert?“ Der Tenor: „Knappe 6h Lebenszeit verloren“ … ganz so dramatisch ist es nicht!
autor

Sven Erik Matzen
Chief eXpertWas ist passiert?
Konsequenzen bei Microsoft
Aufgrund der Kommunikation von Microsoft lautet unsere Einschätzung: Microsoft hat insgesamt einen guten Job gemacht!
- Das Problem wurde sofort kommuniziert – z. B. auf Twitter, also auf einer von Microsoft unabhängigen Plattform.
- Das Netzwerkproblem wurde innerhalb von nur 2 Stunden analysiert und beseitigt. Zusätzlich wurden die Prozesse so angepasst, dass ein solches Problem in Zukunft besser verhindert werden kann.
- Die bis zu 6 Stunden andauernden Auswirkungen wurden analysiert. Dabei wurden Probleme in den betroffenen Produkten identifiziert und zeitgleich behoben.
- 5 Tage nach dem Vorfall wurde ein Post-Incident Report (Tracking ID: VSG1-B90) veröffentlicht, der detailliert beschreibt, was wann passiert ist und welche Maßnahmen getroffen wurden.
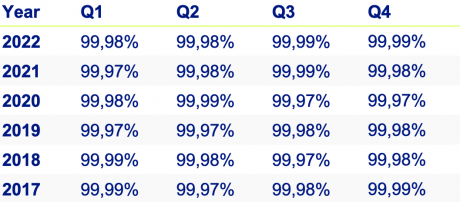
Im Übrigen ist Microsoft sehr transparent, was die Verfügbarkeit seiner Dienste betrifft. Im Zeitraum 2017 bis 2022 betrug die durchschnittliche Verfügbarkeit aller Azure-Dienste 99,98%. Dieser Wert zeigt, wie groß die Investitionen in die Verfügbarkeit sind, denn Microsoft hat kein Interesse an negativen Schlagzeilen, unzufriedenen Kunden und Umsatzverlust.
Konsequenzen für das eigene Business
Eine wichtige Maßnahme: Risikomanagement!
Dabei gelten für in der Cloud betriebene Workloads die gleichen Überlegungen wie für On-Premises-Workloads:
- Potenzieller Impact: Was passiert, wenn der Workload ausfällt? Welche Ausfallzeiten sind maximal vertretbar? Welche Abhängigkeiten zu anderen Systemen/Diensten existieren und wie ist deren Verfügbarkeit?
- Mitigations-Maßnahmen: Welche Gegenmaßnahmen sind erforderlich, um das Risiko eines Ausfalls zu minimieren, und wieviel kosten diese?
Neben den gängigen Maßnahmen wie z. B. Herstellung von Redundanz durch Anwendung einer Multi-Cloud-Strategie (komplex und teuer) ist auch „Resilient Software Design“ als Methode eine valide Option. Resilienz beschreibt hierbei die Fähigkeit des Systems, Ausfälle ohne nennenswerten Impact zu kompensieren. Das bedeutet den Umbau der Prozesse/Workloads so, dass Systemausfälle möglichst wenig Auswirkungen auf den Geschäftsbetrieb haben. Der für einen solchen Umbau anfallende Aufwand ist vom Prozess und der bestehenden Gesamtarchitektur abhängig und kann sich durchaus lohnen.
Netflix hat beispielsweise bereits 2011 ein System implementiert, welches Resilienz „erzwingen“ sollte: Chaos Monkey (netflix.github.io). Die Idee dahinter: Statt im Falle eines Ausfalls zu schauen, was man hätte besser machen können, werden ständig ungeplante Ausfälle simuliert. Das System terminiert hierfür zufällig VMs und/oder Container in der produktiven Umgebung, sodass resilient ausgelegte Dienste einen Vorteil haben. Ein Service, der in diesem Umfeld entwickelt wird, übersteht dann auch real auftretende Ausfälle.
Microsoft 365 Verfügbarkeit
Fazit
Bei sachlicher Betrachtung rechtfertigen die Ereignisse des 25.01. kein grundsätzliches Infragestellen einer vorhandenen Cloud-Strategie. Cloud-Anbieter wie Microsoft investieren immense Summen in die Hochverfügbarkeit ihrer Dienste, da Ausfälle potenziell massiv geschäftsschädigend sind.
Lokale Rechenzentren können dabei bezüglich Redundanz nicht mit den großen Cloud-Anbietern mithalten; Multi-Cloud-Strategien als Alternative sind für viele Kunden zu komplex und teuer.
Ein individuelles Risikomanagement für geschäftskritische Workloads ist also essentiell. Der potenzielle Impact muss dabei gegen die Kosten der Mitigation abgewogen werden. Wo es sich lohnt, empfiehlt sich die konsequente Anwendung von Resilient Software Design.
Resilient Software Design – Grundprinzipien
- Isolation: Schaffung unabhängiger, automomer Einheiten und Isolation von Fehlern
- Redundanz: Gleichzeitiger Betrieb mehrerer Instanzen der autonomen Einheiten, um ein Failover zu ermöglichen
- Lose Kopplung, z. B. durch den Einsatz nachrichtenbasierter Kommunikation
- Fallback-Strategie, die im Fehlerfall angewendet werden soll


Interessiert an Azure-nativer, resilienter Software Architektur?Senden Sie uns eine formlose E-Mail!
E-MailSie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen