Azure OpenAI – erste Schritte
Generative KI • Azure OpenAI • Prompt Engineering

In diesem Beitrag wollen wir einen ersten einfachen Chat-Client mit Azure OpenAI umsetzen. Dazu müssen wir uns mit dem Azure OpenAI Service, Modellen, Prompts und der API auseinandersetzen.
Mit dieser praktischen Einführung sollten sich einige der Grundbegriffe aus dem ersten Beitrag ChatGPT verändert die Softwareentwicklung besser einordnen lassen. Außerdem haben wir damit die Grundlage für spätere Erweiterungen für komplexere Anwendungsfälle.

Die Themen, die wir betrachten müssen, lassen sich wie folgt unterscheiden:
- Zugang: Man bekommt den Azure OpenAI Zugang derzeit nur auf Antrag.
- Modelle: Es gibt unterschiedliche Modelle zur Auswahl.
- Prompts: Wir benötigen ein Grundverständnis zum Aufbau der Prompts.
- API und Programmierung: Schlussendlich müssen wir das Ganze in Code gießen.
Also der Reihe nach…
Zugang
Der erste Schritt geht natürlich in das Azure Portal, um dort den Azure OpenAI Service anzulegen. Der schnelle Link: https://portal.azure.com/#create/Microsoft.CognitiveServicesOpenAI
Allerdings wird man hier (Stand Sept. ´23) mit einer Fehlermeldung begrüßt:
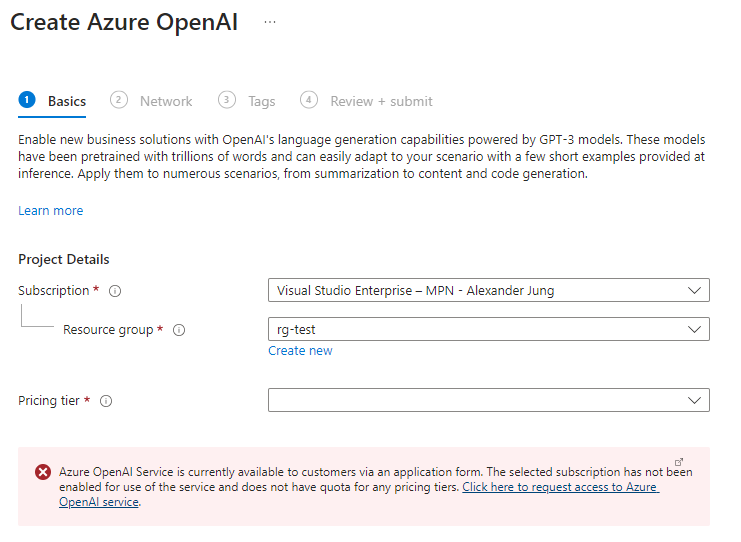
Über den in der Fehlermeldung enthaltenen Link kommt man zu einer Seite, in der man den Zugang zu Azure OpenAI beantragen kann. Dazu sind einige Angaben zur Firma und zur Subscription, für die die Freischaltung erfolgen soll, nötig. Außerdem kann man sich noch für “Text and code models” und “DALL-E 2 models” (für Bildgenerierung) entscheiden.
Die Bestätigungsmail kündigt zwar bis zu 10 Tage Bearbeitungsdauer an, aber die positive Antwort war am gleichen Tag im E-Mail-Eingang. Das reicht für GPT-3.5 und DALL-E; wer GPT-4 ausprobieren will, muss sich nach dieser Bestätigung auf eine Warteliste eintragen. Hier dauerte es bei mir etwas über 2 Wochen, bis zu einer positiven Antwort.
Ist Azure OpenAI einmal verfügbar kann man einen Service anlegen. Dabei muss man auf die Region achten, denn die verschiedenen Modelle sind nur in ausgewählten Regions verfügbar (DALL-E derzeit nur in einer einzigen), man sollte also die Dokumentation prüfen.
Anschließend kann man dann unter „Model deployments“ ins „Azure OpenAI-Studio“ wechseln, um dort seine Modelle zu verwalten.
Modelle
Der erste Schritt im Azure OpenAI-Studio ist das Anlegen eines „Model deployments“, einer Bereitstellung. Eine solche Bereitstellung ist die Voraussetzung für jeden Aufruf der API.
Dabei muss man sich für das Basismodell entschieden:
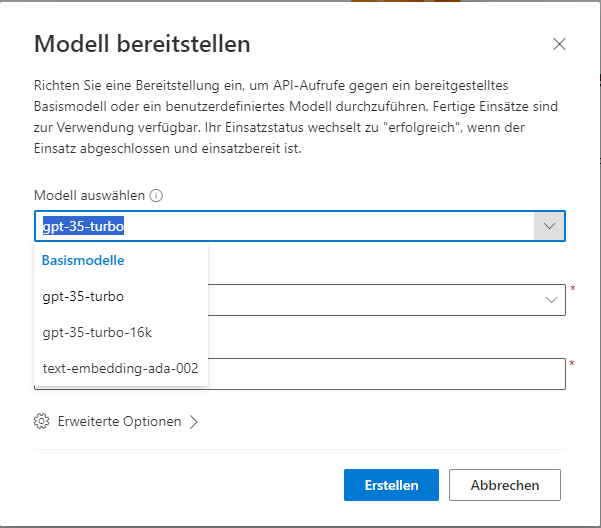
Die Auswahl der Modelle ist beschränkt, und ihr Einsatzzweck dokumentiert, so dass man sich um Details hier nicht allzu viele Gedanken machen muss.
Damit steht das eigene Deployment zur Verfügung:
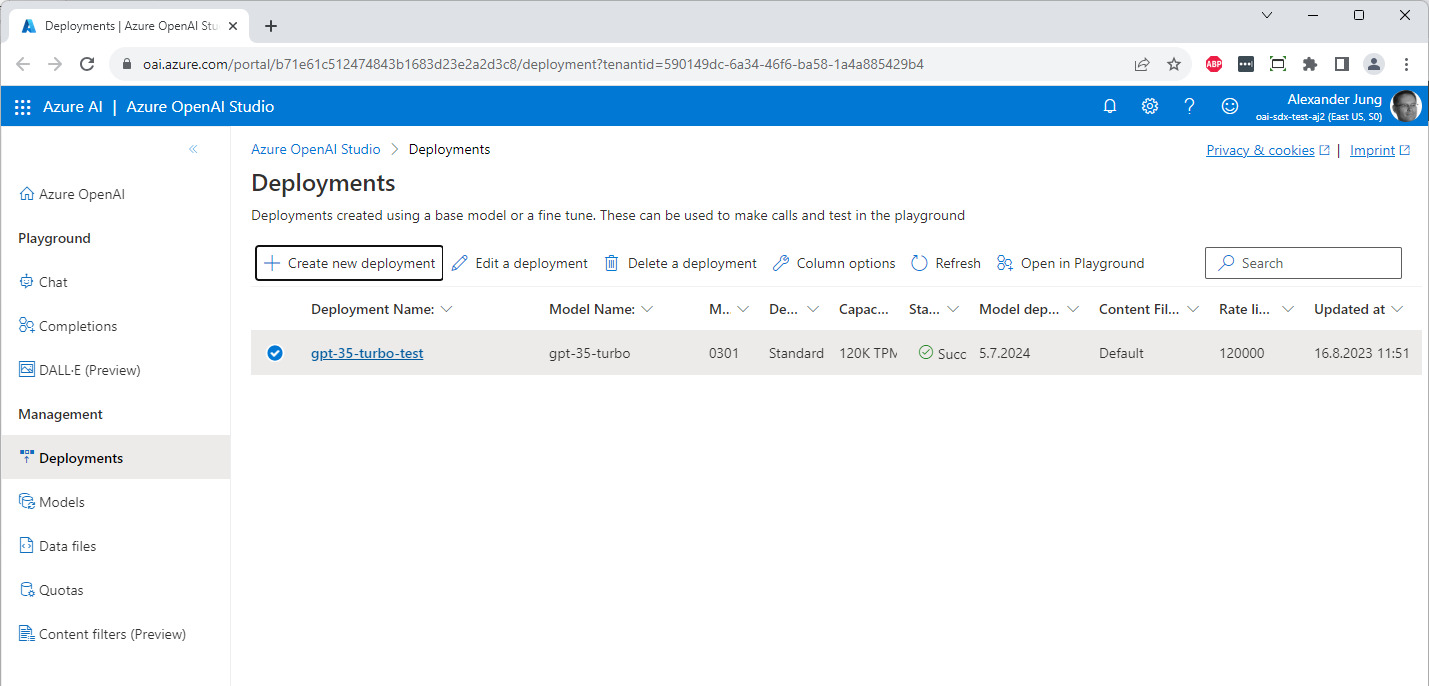
Außerdem erlaubt das Azure OpenAI-Studio das Hochladen und Verarbeiten eigener Trainingsdaten. Aber das würde den Rahmen dieses Beitrags sprengen. Und man sollte sich klarmachen, dass spätestens ab diesem Zeitpunkt die Stunde von AI- und Data Engineers schlägt.
Prompts
Der Bereich „Playground“ erlaubt das Testen der bereitgestellten Modelle, so dass man schnell Ergebnisse sieht:
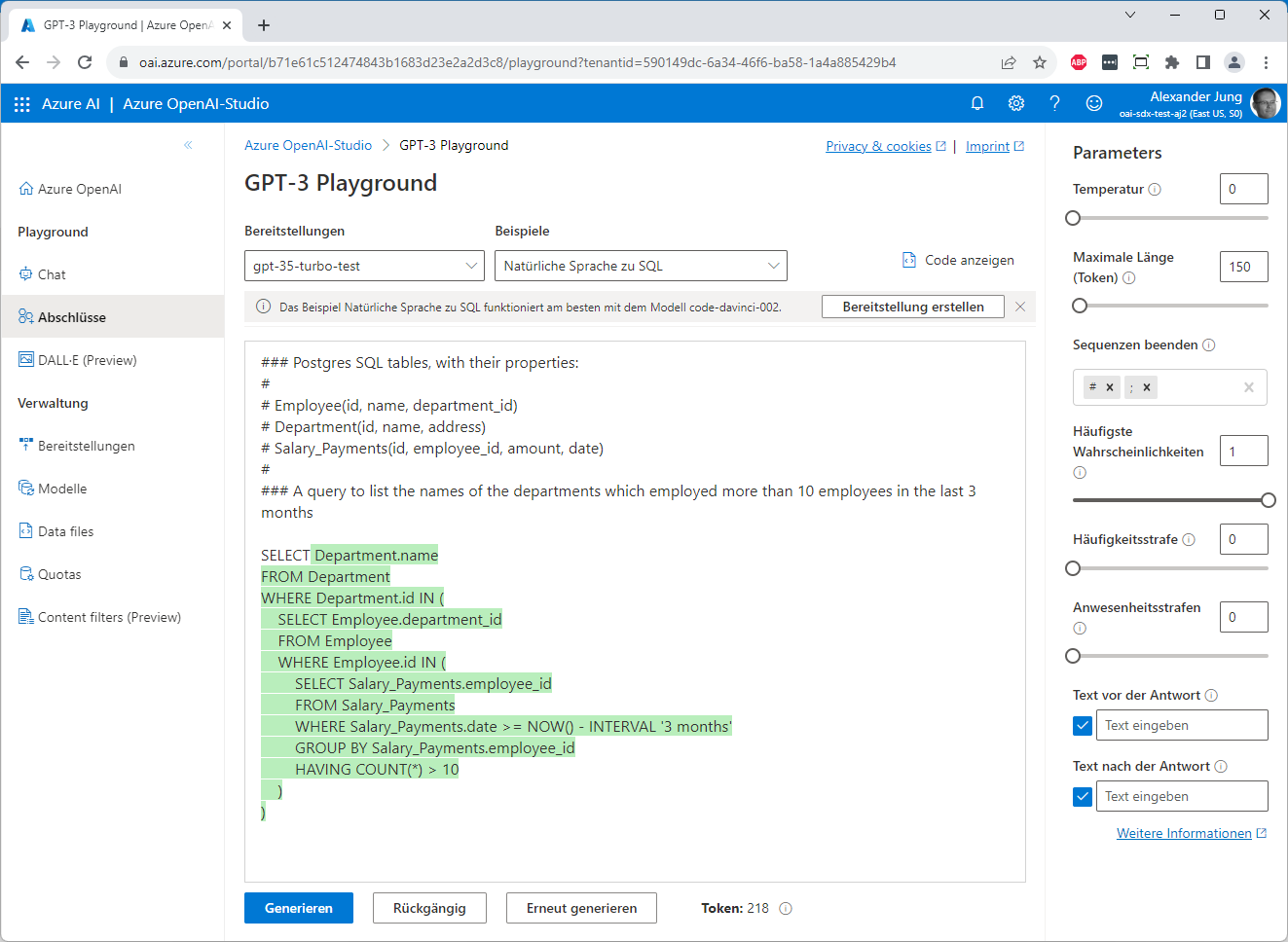
Der „normale“ Text im Eingabefeld ist die Anfrage, das Prompt; der grün dargestellte Text wurde vom Modell generiert.
Das leitet auch gleich zu einer grundlegenden Verständnisfrage über: Es liegt nahe, sich einen Chat als einen Dialog zwischen zwei Beteiligten vorzustellen. Tatsächlich ist es jedoch so, dass Prompt-basierte Modelle nicht eine Antwort liefern – also reagieren –, vielmehr nehmen sie den übergebenen Text (den Prompt) und schrieben ihn fort. Sie vervollständigen ihn (daher „Completion“) aufgrund ihres statistischen „Wissens“.
Ein anderes Beispiel, bei dem das etwas deutlicher wird:

Dieses Vervollständigen lässt sich über die Art beeinflussen, in der der Prompt aufgebaut ist. Dazu gehören spezifischere Informationen, Beispiele, Angaben, wie sich der Service „verhalten“ soll, Hinweise zum gewünschten Format der Antwort und anderes. Unter „Introduction to prompt engineering” geht Microsoft auf dieses Thema ein und gibt Hinweise, worauf man achten sollte.
Bei Chat Completions besteht der Prompt nicht mehr aus einem einfachen Text, sondern aus einer Liste von Texten mit Rollen. Text in der Rolle „System“ gibt man dem Aufruf initial mit, um vom System bereitgestellte Informationen zu übergeben. Bei einem Fahrplanauskunftssystem könnte dies etwa „Du befindest Dich im Bahnhof Mainz und es ist 8:33.“ sein.
Dem schließt sich zunächst ein Text mit der Rolle „User“ für die Frage des Anwenders an, etwa „Wann geht der nächste Zug nach Frankfurt?“. Die Antwort, die man darauf erhält, wird mit der Rolle „Assistant“ ergänzt, bevor die neue Frage angehängt wird. So baut sich die Konversation – Neudeutsch Chat-Verlauf – nach und nach auf und wird bei jedem Aufruf vollständig wieder an den Service übergeben.
Auch zu Chat Completions hat Microsoft weitere Informationen.
Die Frage, wann man einfache Completions nutzt, und wann Chat Completions, ist übrigens einfach (aber nicht offensichtlich) zu beantworten: Completions sollten für ältere GPT-3-Modelle genutzt werden, Chat Completions für die aktuellen GPT-35-Turbo- und GPT-4-Modelle. Wer neu einsteigt, kann einfache Completions folglich einfach ignorieren.
API und Programmierung
Zeit, das Gelernte in Code zu gießen.
Für eine einfache Kommandozeilenanwendung benötigen wir lediglich eine Nuget-Referenz auf Azure.AI.OpenAI.
Der OpenAI Service wird durch seine Adresse und einen Key bestimmt, beides findet man im Azure Portal unter „Keys and Endpoint“. Die Verbindung wird über ein Client-Objekt hergestellt:
private static OpenAIClient CreateOpenAIClient()
{
var endpoint = new Uri(OpenAIServiceEndpoint);
var keyCredential = new AzureKeyCredential(OpenAIServiceKey);
return new OpenAIClient(endpoint, keyCredential);
}
Die Parameter für die jeweiligen Aufrufe werden in einer Klasse vom Typ ChatCompletionsOptions übergeben:
private static ChatCompletionsOptions CreateChatCompletionsOptions()
{
var chatCompletionsOptions = new ChatCompletionsOptions
{
Temperature = 0f,
MaxTokens = 800,
NucleusSamplingFactor = 1f,
FrequencyPenalty = 0,
PresencePenalty = 0
};
var systemMessage = new ChatMessage(ChatRole.System, SystemPrompt);
chatCompletionsOptions.Messages.Add(systemMessage);
return chatCompletionsOptions;
}
Nebenbei: Die Bezeichnung „Options“ ist unglücklich, denn Options hat in den Microsoft Extensions eine andere Bedeutung.
ChatCompletionsParameterswäre passender gewesen.
Die einzelnen Parameter entsprechen den Werten, die man im Azure OpenAI-Studio (vergleiche oben) rechts an der Seite sieht. Außerdem wird hier exemplarisch ein System-Prompt mitgegeben:
private const string SystemPrompt = "Leite alle Antworten mit \"Ich, DEIN CHAT, sage Dir: \" ein.";
Mit dieser Vorbereitung lässt sich ein einfacher Chat-Client umsetzen:
public static async Task Main(string[] args)
{
var openAiClient = CreateOpenAIClient();
var chatCompletionsOptions = CreateChatCompletionsOptions();
while (true)
{
Console.Write("Frage eingeben: ");
var question = Console.ReadLine();
if (string.IsNullOrEmpty(question))
break;
var answer = await GetChatCompletionsAsync(openAiClient, chatCompletionsOptions, question);
Console.WriteLine(answer);
Console.WriteLine();
}
}
Da die chatCompletionsOptions immer wieder übergeben werden, bleibt der Chat-Verlauf erhalten.
Der interessante Teil findet in der Methode GetChatCompletionsAsync statt:
private static async Task<string> GetChatCompletionsAsync(
OpenAIClient openAiClient, ChatCompletionsOptions chatCompletionsOptions, string question)
{
// prepare options
var questionMessage = new ChatMessage(ChatRole.User, question);
chatCompletionsOptions.Messages.Add(questionMessage);
// Call...
var response = await openAiClient.GetChatCompletionsStreamingAsync(ChatModel, chatCompletionsOptions);
var completions = response.Value;
if (completions is null)
return "The request resulted in no answer.";
// process result...
var answer = await GetAnswerAsync(completions);
var answerMessage = new ChatMessage(ChatRole.Assistant, answer);
chatCompletionsOptions.Messages.Add(answerMessage);
return answer;
}
Im ersten Schritt wird die gerade eingelesene Frage mit der Rolle „User“ in den Parametern ergänzt. Nach dem Aufruf und dem Auslesen der Antwort wird auch diese, diesmal mit der Rolle „Assistant“ angefügt.
Das Auslesen der Antwort ist hingegen – im ersten Moment vielleicht überraschend – etwas aufwendiger und deshalb in eine eigene Methode ausgelagert:
private static async Task<string> GetAnswerAsync(StreamingChatCompletions completions)
{
var sb = new StringBuilder();
var choices = completions.GetChoicesStreaming();
await foreach (var choice in choices)
{
var messageStreaming = choice.GetMessageStreaming();
await foreach (var message in messageStreaming)
sb.Append(message.Content);
sb.AppendLine();
}
return sb.ToString();
}
Man erhält potenziell mehrere Antwortmöglichkeiten – das lässt sich über die ChatCompletionsOptions steuern (hier wird davon kein Gebrauch gemacht, der Standard ist 1). Und jede Teilantwort kommt in Einzelteilen, üblicherweise wortweise.
Und hier der Nachweis, dass der OpenAI-Service funktioniert:
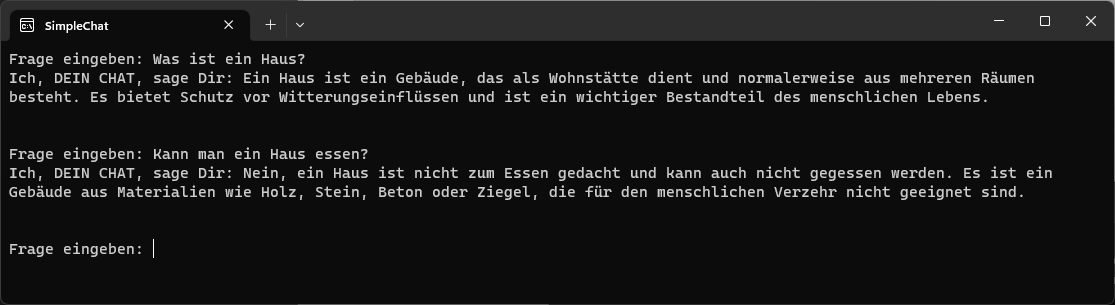
Die zweite Frage macht wenig Sinn und der Service antwortet entsprechend. Startet man die Anwendung aber neu und schiebt eine Frage dazwischen, dann wird der Bezug klar, und der Service liefert eine entsprechend angepasste Antwort:
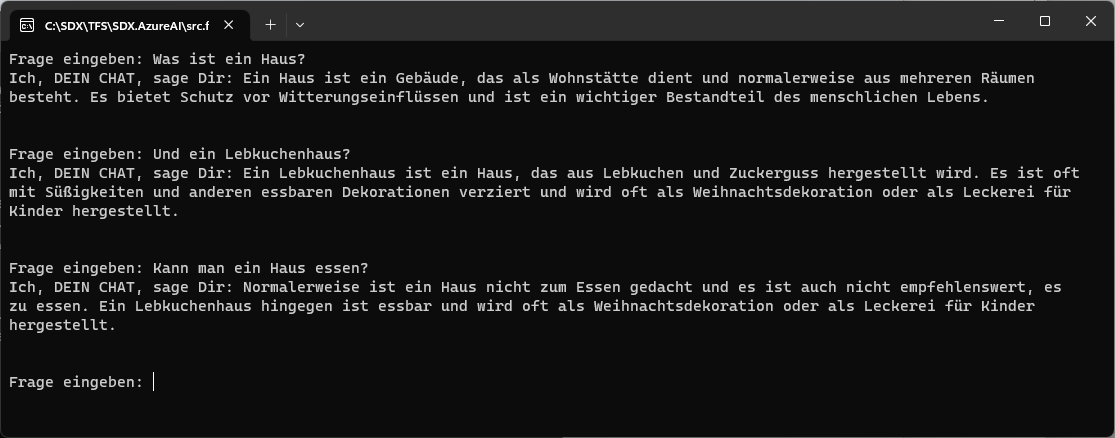
Übrigens können die Antwortzeiten stark schwanken. Von 2 Sekunden bis zu einer Minute waren typische Werte, die wir beobachtet haben. Grund sind rate limits, die man aber (in Grenzen) einstellen kann.
Fazit
Da ist er, unser erster eigener Chat. Der Code dafür ist relativ einfach und nachvollziehbar; es ist eher das ganze Drumherum, mit dem man sich auseinandersetzen muss.
Das ist aber nur der erste Schritt. Interessant wird es erst, wenn ich Fragen zu eigenen Inhalten stellen und die Antwort sinnvoll (also in der Regel nicht als Prosa) weiterverarbeiten kann.
Aber dafür wird es weitere Beiträge geben.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen