Data Analytics automatisieren mit der Azure Data Factory

In meinem letzten Flurfunk-Artikel „Aus der Praxis: Beschleunigte Analyse von Log-Dateien mit Azure Data Lake Analytics“ habe ich beschrieben, wie mithilfe von Azure Functions und Azure Data Lake Analytics Logdateien aus komprimierten Archiven extrahiert und parallel analysiert werden können.
Ursprünglich wurde die beschriebene Verarbeitungsstrecke für den manuellen Einsatz mit flexiblen Parametern entwickelt. So kann der Anwender entscheiden, welche Dateien aus welchen Archiven gebraucht werden, und sein U-SQL-Skript entsprechend der jeweiligen Datenstruktur und der zu beantwortenden Fragestellung anpassen.
Für ganz konkrete, wiederkehrende Fragestellungen lässt sich dieser Ablauf jedoch auch leicht automatisieren. Das bevorzugte Werkzeug auf Microsoft Azure ist dabei die Azure Data Factory. In diesem Artikel möchte ich das Beispiel der Log-Analyse anhand eines umgesetzten Prototypen auf einen bestimmten Anwendungsfall konkretisieren und die Möglichkeiten und Einschränkungen bei der Automatisierung mithilfe der Azure Data Factory aufzeigen.
Die Azure Data Factory
Vor der Beschreibung des konkreten Beispiels soll hier kurz ein Überblick über die Azure Data Factory gegeben werden. Die Data Factory ist ein Orchestrierungsservice auf Microsoft Azure, mit dessen Hilfe Daten zwischen Systemen verschoben, Aktionen ausgelöst und andere Services gesteuert werden können. Die Verarbeitungsstrecke wird dabei über drei verschiedene Arten von Komponenten definiert:
Linked Services
Ein Linked Service kann grundsätzlich alles sein, das über eine Schnittstelle ansprechbar ist. Dazu gehören die meisten Azure Services – von Storage Accounts über Azure Function Apps bis hin zu Data Lake Analytics und Machine Learning Studio – aber auch externe Datenquellen wie AWS-Speicher, On-Premises Datenbanken und jeder beliebige Webservice mit einem http-Endpunkt. Über die Definition eines Linked Services werden diese Endpunkte der Data Factory bekannt gemacht. In der Regel müssen dabei entsprechende Credentials angegeben werden, die es der Factory erlauben, sich gegenüber dem jeweiligen Dienst zu authentifizieren. Dazu mehr im Abschnitt Authentifizierung.
Datasets
Datasets kommen immer dann zum Einsatz, wenn die Data Factory selbst auf Daten zugreifen und diese verarbeiten (auslesen oder verschieben) soll. Ein Dataset stellt dabei eine konkrete Datenstruktur (Datei, Tabelle, WebResponse) innerhalb eines Connected Service dar und kann sowohl als Input als auch als Output dienen. Je nach Einsatzzweck müssen die Daten mit einem konkreten Schema beschrieben werden (z.B. zum Kopieren in eine SQL-Tabelle) oder können als Binary Data behandelt werden (z.B. zum Kopieren von Bilddateien). Die Data Factory unterstützt auch die automatische Kompression bzw. Dekompression bestimmter Formate (zip, gzip, bzip2). Die Verwendung von Parametern erlaubt es, Datasets flexibel zu definieren und an verschiedenen Stellen wiederzuverwenden.
Pipelines
Eine Pipeline beschreibt den konkreten Ablauf einer automatischen Verarbeitung. Hier werden sogenannte Activities definiert, in denen Connected Services und Datasets verwendet werden, um Aktionen durchzuführen oder Daten zu verschieben. Sie weisen dadurch eine große Ähnlichkeit mit SSIS-Paketen auf. Wie Datasets können auch Pipelines parametrisiert und entsprechend bei der Ausführung gesteuert werden.
Definition der Komponenten
Alle drei Arten von Komponenten der Data Factory können entweder über die grafische Benutzeroberfläche des Azure Portals oder mithilfe von ARM-Templates definiert werden. Beide Varianten lassen sich jederzeit ineinander überführen. So bietet jeder Teilbereich in der Oberfläche der Data Factory einen „Code“-Button, mit dem sich die JSON-ARM-Definition des gerade bearbeiteten Elements anzeigen und bearbeiten lässt.
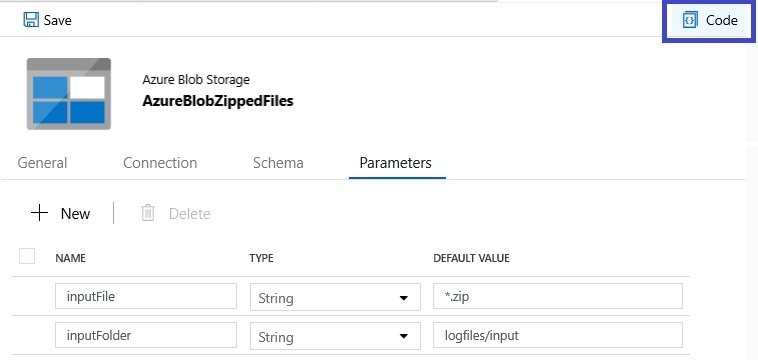
Ein Klick auf die Schaltfläche (blau umrandet) ruft in Fall dieses Datasets die folgende Definition auf:

An diesem Beispiel lässt sich unter anderem die Definition und Verwendung von Parametern erkennen. Sowohl der Ordner als auch der Dateiname, auf die das Dataset verweist, können von außen vorgegeben werden. Damit lässt sich dieses Dataset für sämtliche zip-komprimierten Dateien innerhalb des verlinkten Blob-Storages verwenden. Der Storage Account selbst wird nicht hier im Dataset, sondern im Connected Service (an dieser Stelle „AzureBlob“ genannt) definiert, sodass die Verbindungsinformationen nur einmal hinterlegt werden müssen.
Trigger
Eine vierte zentrale Komponente innerhalb der Azure Data Factory sind die Trigger, mit denen sich die Ausführung einer Pipeline einplanen bzw. anstoßen lässt. Zwar kann eine Pipeline grundsätzlich auch manuell gestartet werden, das ist jedoch eher für Entwicklungs- und Testzwecke relevant.
Im Wesentlichen stehen zwei Arten von Triggern zur Verfügung: Zeitgesteuert und Eventgesteuert.
Zeitgesteuerte Trigger können benutzt werden, um Pipelines in regelmäßigen Abständen (Minuten bis Monate) auszuführen. Interessant ist dabei, dass das Startdatum auch in der Vergangenheit liegen darf. Die Data Factory wird dann bei Aktivierung des Triggers sämtliche verpassten Zeitfenster nachholen. Das jeweilige Datum der Ausführung kann deshalb als Parameter innerhalb der Pipeline genutzt werden, um bspw. die passenden Daten für den Zeitraum auszuwählen.
Eventgesteuerte Trigger können aktuell nur auf das Anlegen oder Löschen einer Datei im Azure Blob Storage reagieren. Möchte man eine Pipeline über andere Events (http, Queue-Storage, Eventhub, …) auslösen, führt der beste Weg deshalb über eine Azure Function mit entsprechendem Trigger, die lediglich einen Blob auf den Storage legt, auf den wiederum die Data Factory reagiert. Da die Data Factory grundsätzlich für große, langlaufende Verarbeitungen gedacht ist, wäre bei solchen „Notlösungen“ allerdings zu hinterfragen, ob eine eventgesteuerte Ausführung wirklich der optimale Weg ist.
Authentifizierung
Ein durchaus relevanter Faktor beim Einsatz der Azure Data Factory ist die Authentifizierung gegenüber den angebundenen Datenquellen. Anders als beispielsweise für Azure SQL Server gibt es im Fall der Data Factory keine Option, die den automatischen Zugriff auf andere Azure Services in derselben Subscription zulässt. Auch ein Übertragen der Rechte des erstellenden Nutzers auf die Factory oder eine Pipeline ist nicht möglich. Stattdessen wird für jede Data Factory im Azure Active Directory ein eigener Principal angelegt, unter dem sämtliche Pipelines ausgeführt werden. Zur Authentifizierung beispielsweise auf den Data Lake Storage kann diesem Principal das Zugriffsrecht auf den benötigten Ordnern verliehen werden. Beim Anlegen des Connected Services für den ADLS muss dann nur noch die Option „Managed Identity“ ausgewählt werden.
Grundsätzlich ist die Art der möglichen Authentifizierung je nach Connected Service jedoch stark unterschiedlich. Azure Storage unterstützt neben dem Zugriff über die Managed Identity auch die Angabe des Account Keys oder einer Shared Access Signature (SAS).
Eine für die meisten Azure Services geeignete und daher empfohlene Vorgehensweise ist die Verwendung eines Service Principals, also das manuelle Anlegen einer Identität mit entsprechenden Rechten im Azure Active Directory (Anleitung) und einem oder mehreren Secrets. Diese können beim Erstellen des Connected Services entweder direkt oder als Eintrag in der Azure Key Vault angegeben werden. Für den Zugriff von der Data Factory auf Azure Data Lake Analytics und für die Ausführung von U-SQL-Skripten ist der Service Principal sogar die einzige unterstützte Option.
Für den Zugriff auf Endpunkte außerhalb von Azure (AWS, http, Office365, …) ist eine individuelle Betrachtung der erforderlichen bzw. möglichen Authentifizierungs-Optionen notwendig.
Das Beispiel – Hintergrund und Zielstellung
Für diejenigen, die den eingangs verlinkten Artikel nicht gelesen haben, sei an dieser Stelle der Hintergrund kurz zusammengefasst: Die Mitarbeiter eines Kundenunternehmens verwenden Geräte mit angepasster Software. Auf jedem dieser Geräte werden die Logdaten des Systems und der einzelnen Applikationen gesammelt und in komprimierter Form auf einem Azure Blob Storage abgelegt. Aufgrund der Vielzahl von Geräten (7000+), des Datenumfangs (ca. 2,5 GB pro Gerät) und der Heterogenität in Art und Struktur der einzelnen Logs ist eine manuelle Analyse auf einem lokalen Entwicklergerät schwierig und aufwendig. Deshalb wurde wie eingangs beschrieben ein Prozess in der Cloud entwickelt, mit dem einzelne Logdateien je nach Bedarf extrahiert und analysiert werden können.
Für die Automatisierung braucht es dagegen eine ganz konkrete und immer wiederkehrende Fragestellung. Im Beispiel dieses Prototypen sollen aus allen neu hochgeladenen Logdaten automatisch die Fehlermeldungen aus der Datei ErrorLogging.log ausgelesen und mit denen anderer Geräte verglichen werden, um Anomalien, also ungewöhnliche Häufungen von bestimmten Fehlern, zu erkennen und darauf zu reagieren.
Die eigentliche Erkennung der Abweichungen soll nicht Thema dieses Artikels sein. Sie wurde für den Prototypen mithilfe von Clustering-Algorithmen umgesetzt. Eine ausführliche Beschreibung würde an dieser Stelle jedoch zu weit führen und den Umfang des Beitrags sprengen.
Umsetzung
Die für den Prototypen aufgesetzte Pipeline ist im folgenden Bild dargestellt. Die Pipeline wird eventgesteuert getriggert und reagiert auf den Upload eines Log-Archivs.
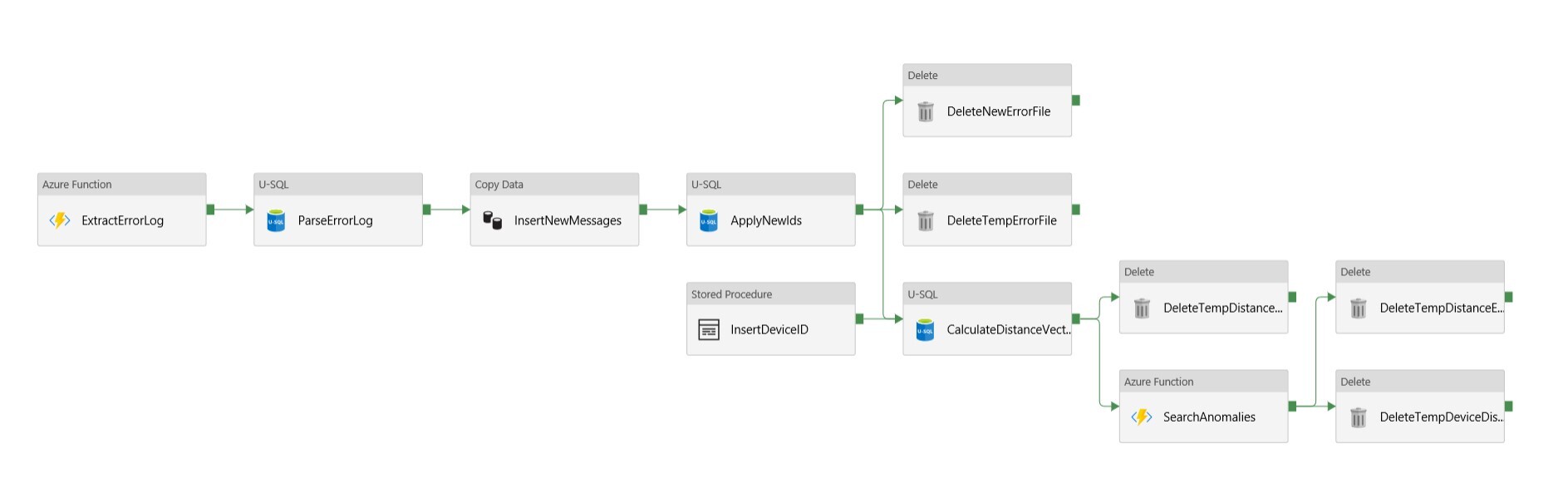
Die Verarbeitung lässt sich dabei in folgende wesentliche Punkte zusammenfassen:
Extraktion: Zuerst muss aus dem hochgeladenen Archiv die Datei ErrorLogging.log extrahiert werden. Dazu wird die bereits vorhandene Azure Function aus dem eingangs verlinkten Artikel verwendet. Sie bekommt das aktuelle Archiv und den Namen der gesuchten Datei als Parameter beim http-Request übergeben und legt die Datei auf dem Azure Data Lage Storage ab.
Fehler-Aufbereitung: Sobald die Log-Datei in extrahierter Form im Data Lake vorliegt, müssen die darin enthaltenen Fehlermeldungen verarbeitet und in eine einheitliche Form gebracht werden. Konkret werden sämtliche Parameter entfernt und die unhandlichen Text-Nachrichten durch Zahlen ersetzt. Diese werden anschließend aggregiert, um die Häufigkeit der einzelnen Fehler für das aktuelle Gerät mit denen der anderen Geräte vergleichen zu können. Dies geschieht in insgesamt drei U-SQL-Skripten.
Reaktion: Für den Fall, dass auffällige Abweichungen in den Fehlermeldungen gefunden wurden, wird eine automatische E-Mail-Nachricht über SendGrid on Azure versendet. Der Code dafür steckt in einer zweiten Azure Function. Ein Beispiel für eine solche E-Mail ist im folgenden Bild zu sehen.

Alle weiteren, bisher nicht erwähnten Activities lassen sich unter dem Schlagwort „Datentransfer“ zusammenfassen und sind überwiegend Aktionen, die die Data Factory selbst übernimmt (Copy Data, Delete). Sie sind allerdings gut geeignet, um ein Gefühl für die Möglichkeiten und die Einschränkungen bei der Arbeit mit der Data Factory und insbesondere Data Lake Analytics zu gewinnen:
Wie beschrieben werden die Texte aus den Fehlermeldungen während der Analyse auf IDs gemappt. Das gleiche gilt für den Namen des Gerätes. Da allerdings mehrere dieser Pipelines gleichzeitig ausgeführt werden können, braucht es eine zentrale Instanz, die die Vergabe dieser IDs regelt, um die Eindeutigkeit zu gewährleisten. Dazu bietet sich eine relationale Datenbank an. Im Rahmen des Prototypen wurden zwei Tabellen mit Identity-Spalte in einer Azure SQL DB verwendet.
Azure Data Lake Analytics bzw. U-SQL unterstützt auch die Einbindung von SQL-Server-Datenbanken als external Data Source. Allerdings kann darüber nur lesend auf die Daten zugegriffen werden. Das Einfügen in Datenbank-Tabellen muss außerhalb von U-SQL erfolgen. Deshalb gibt es in der Pipeline die beiden Aktivitäten InsertNewMessages, die alle bisher unbekannten Fehlermeldungen aus dem Ergebnis der ersten U-SQL-Ausführung in die Datenbank überträgt, und InsertDeviceID, die die ID des aktuellen Geräts über eine Stored Procedure anlegt, falls sie noch nicht vorhanden ist. Danach kann davon ausgegangen werden, dass sowohl alle Message-Texte als auch alle bekannten Geräte eindeutige numerische IDs besitzen.
Ein zweites Hindernis beim Verknüpfen von U-SQL-Aktivitäten ist die Übertragung von Daten aus einem Skript zum nächsten. Der Azure Data Lake bietet neben dem reinen Dateispeicher auch interne Datenbanken an. In diesen können aus U-SQL heraus relationale Tabellen angelegt, befüllt und abgefragt werden. Diese Tabellen haben allerdings einen eingeschränkten Funktionsumfang. Zum Beispiel gibt es keine Identity-Spalten und es werden lediglich Insert und Select unterstützt. Ein Update oder Delete ist nur über das Löschen ganzer Partitionen möglich. Deshalb ist es oft einfacher, die Ergebnisse eines Skripts für die Weiterverarbeitung stattdessen in Dateiform auf dem Data Lake Storage abzulegen. Die Delete-Aktivitäten in der Pipeline sorgen dafür, dass diese temporären Dateien wieder entfernt werden, sobald sie für die Verarbeitung nicht mehr benötigt werden.
Orchestrierung der Pipeline
Die oben beschriebene Pipeline zum Entpacken und Analysieren des ErrorLogs arbeitet auf den Daten eines einzelnen Gerätes und reagiert auf den Upload neuer Daten in den Blob-Storage. Um diese Verarbeitung auf bereits vorhandene Daten anzuwenden bzw. allgemein, um Pipelines auf größeren Batches auszuführen, bietet die Azure Data Factory die Option, Pipelines als Aktivität innerhalb anderer Pipelines auszuführen.
Für den konkreten Prototypen wurde eine zweite Pipeline definiert, die diese Aufgabe für eine Menge von Geräten übernimmt. Diese ist in der folgenden Abbildung dargestellt, wobei die eigentliche Ausführung der Sub-Pipeline innerhalb der ForEach-Aktivität stattfindet.

Leider scheint es in der Data Factory keine direkte Option zu geben, um direkt über eine Menge von Dateien im Blob Storage zu iterieren. Stattdessen wurde hier erneut auf eine Azure Function zurückgegriffen, um die Namen aller hochgeladenen Archive aufzusammeln. Man hätte diese Liste dann entweder direkt von der Function zurückgeben lassen können oder, wie hier geschehen, in eine neue Datei schreiben lassen. Die Lookup-Aktivität lädt die Namensliste aus dieser Datei und übergibt sie an die ForEach-Aktivität, die wiederum für jeden Eintrag in der Liste die Analyse-Pipeline aufruft. Am Ende wird die erzeugte Datei wieder entfernt.
Mithilfe dieser äußeren Pipeline war es möglich, die Verarbeitung ohne Anpassungen über eine größere Menge von Dateien laufen zu lassen. Das Vorgehen hat sich jedoch als ineffizient erwiesen. Zum einen kann durch die Einzelverarbeitung die hohe Parallelität von Data Lake Analytics nicht genutzt werden. Zum anderen entstehen auf diese Weise vergleichsweise hohe Kosten aufseiten der Data Factory. Für gerade einmal 800 verarbeitete Geräte lag der Preis allein für die Factory bei ca. 18 Euro – gegenüber 5 Euro für Data Lake Analytics, wo die eigentliche Analyse stattfand. Von diesen 18 Euro entfallen mehr als 11 auf den Block „data movement“ – obgleich jede der bewegten Dateien nur wenige hundert bis tausend Byte groß gewesen sein dürfte. Die übrigen 7 Euro stehen für die „orchestration“, werden also durch den massenhaften Aufruf der Unter-Pipelines verursacht.
Ein effizienteres und wohl auch billigeres Vorgehen wäre es also, nur die Azure Funktion zum Entpacken der ErrorLogs aus den Archiven in einer ForEach-Aktivität aufzurufen und die nachfolgenden U-SQL-Skripte so anzupassen, dass sie direkt auf der Gesamtmenge der Daten arbeiten. Auf diese Weise könnte die Stärke von Data Lake Analytics zum Tragen kommen und der Aufruf hunderter Sub-Pipelines entfallen.
Fazit
Mithilfe der Azure Data Factory können einzelne Komponenten innerhalb und außerhalb von Azure bequem und schnell zu zusammenhängenden Pipelines verbunden und orchestriert werden. Während gewisse funktionale Einschränkungen und Authentifizierungs-Hürden den Einstieg erschweren, ermöglicht die Parametrisierung sämtlicher Komponenten innerhalb der Pipeline einen guten Grad an Flexibilität und Wiederverwertbarkeit. Fehlende Funktionalität kann zudem recht einfach durch eigenen Code in Form von Azure Functions oder Custom-Activities ergänzt werden.
Für einen Prototypen zur allgemeinen Demonstration und Analyse der verschiedenen Optionen und Möglichkeiten innerhalb der Azure Data Factory hat sich die umgesetzte Lösung als vielversprechend erwiesen. Sie zeigt eindrucksvoll das Potential wie auch die Hindernisse dieser Art der Automatisierung auf. Sie verdeutlicht aber auch, dass beim Aufbau der Pipeline, wie bei vielen Azure Services, sorgfältige Planung und Optimierung entscheidend sind, um tatsächlich von den Vorteilen der Cloud hinsichtlich Geschwindigkeit, Kosten und Skalierung zu profitieren.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr InformationenSie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Mehr Informationen